 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Equivalent Substitution Training for Large-Scale Recommender Systems
Paper and Code
Sep 10, 2019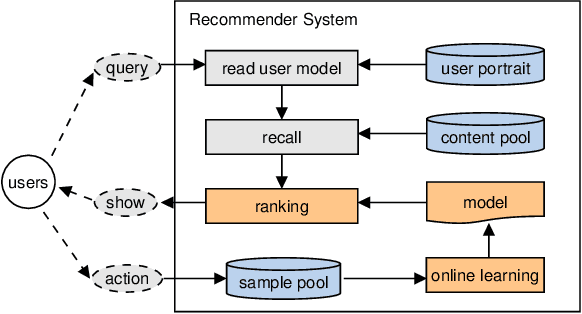
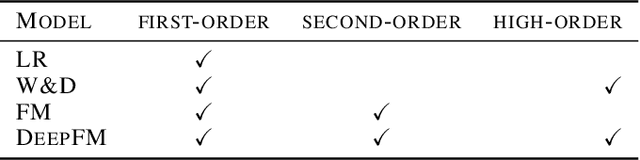
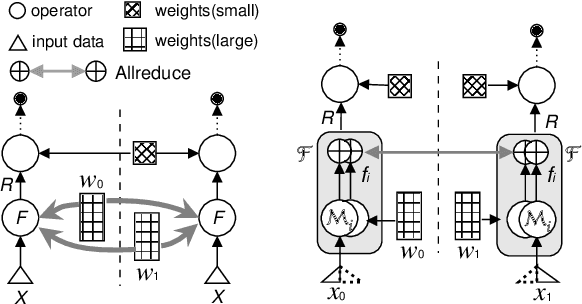
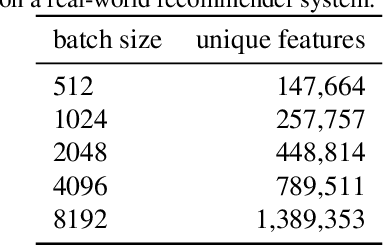
We present Distributed Equivalent Substitution (DES) training, a novel distributed training framework for recommender systems with large-scale dynamic sparse features. Our framework achieves faster convergence with less communication overhead and better computing resource utilization. DES strategy splits a weights-rich operator into sub-operators with co-located weights and aggregates partial results with much smaller communication cost to form a computationally equivalent substitution to the original operator. We show that for different types of models that recommender systems use, we can always find computational equivalent substitutions and splitting strategies for their weights-rich operators with theoretical communication load reduced ranging from 72.26% to 99.77%. We also present an implementation of DES that outperforms state-of-the-art recommender systems. Experiments show that our framework achieves up to 83% communication savings compared to other recommender systems, and can bring up to 4.5x improvement on throughput for deep models.