 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLSeg: Image and Video Segmentation as Multi-Label Classification and Selected-Label Pixel Classification
Paper and Code


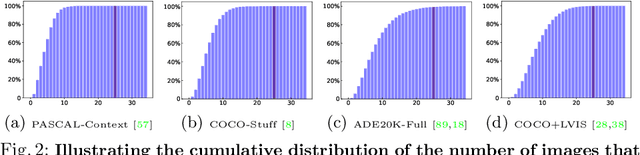
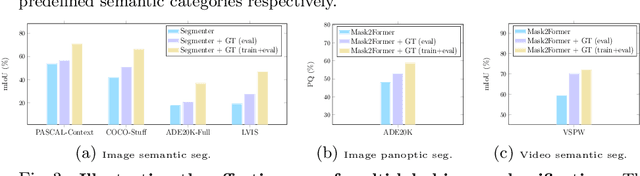
For a long period of time, research studies on segmentation have typically formulated the task as pixel classification that predicts a class for each pixel from a set of predefined, fixed number of semantic categories. Yet standard architectures following this formulation will inevitably encounter various challenges under more realistic settings where the total number of semantic categories scales up (e.g., beyond $1\rm{k}$ classes). On the other hand, a standard image or video usually contains only a small number of semantic categories from the entire label set. Motivated by this intuition, in this paper, we propose to decompose segmentation into two sub-problems: (i) image-level or video-level multi-label classification and (ii) pixel-level selected-label classification. Given an input image or video, our framework first conducts multi-label classification over the large complete label set and selects a small set of labels according to the class confidence scores. Then the follow-up pixel-wise classification is only performed among the selected subset of labels. Our approach is conceptually general and can be applied to various existing segmentation frameworks by simply adding a lightweight multi-label classification branch. We demonstrate the effectiveness of our framework with competitive experimental results across four tasks including image semantic segmentation, image panoptic segmentation, video instance segmentation, and video semantic segmentation. Especially, with our MLSeg, Mask$2$Former gains +$0.8\%$/+$0.7\%$/+$0.7\%$ on ADE$20$K panoptic segmentation/YouTubeVIS $2019$ video instance segmentation/VSPW video semantic segmentation benchmarks respectively. Code will be available at:https://github.com/openseg-group/MLSeg