 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSC3OD: Sparsely Supervised Collaborative 3D Object Detection from LiDAR Point Clouds
Paper and Code
Jul 03, 2023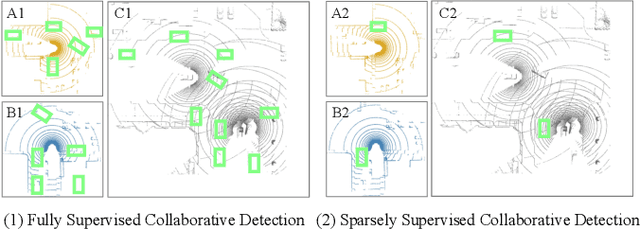

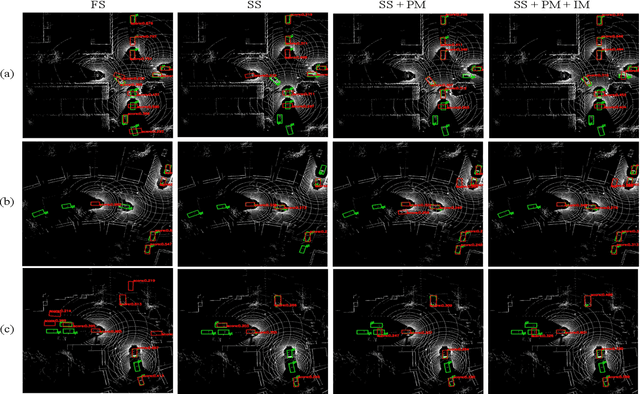

Collaborative 3D object detection, with its improved interaction advantage among multiple agents, has been widely explored in autonomous driving. However, existing collaborative 3D object detectors in a fully supervised paradigm heavily rely on large-scale annotated 3D bounding boxes, which is labor-intensive and time-consuming. To tackle this issue, we propose a sparsely supervised collaborative 3D object detection framework SSC3OD, which only requires each agent to randomly label one object in the scene. Specifically, this model consists of two novel components, i.e., the pillar-based masked autoencoder (Pillar-MAE) and the instance mining module. The Pillar-MAE module aims to reason over high-level semantics in a self-supervised manner, and the instance mining module generates high-quality pseudo labels for collaborative detectors online. By introducing these simple yet effective mechanisms, the proposed SSC3OD can alleviate the adverse impacts of incomplete annotations. We generate sparse labels based on collaborative perception datasets to evaluate our method. Extensive experiments on three large-scale datasets reveal that our proposed SSC3OD can effectively improve the performance of sparsely supervised collaborative 3D object detectors.