 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity-Graph Enhanced Cross-Modal Pretraining for Instance-level Product Retrieval
Paper and Code


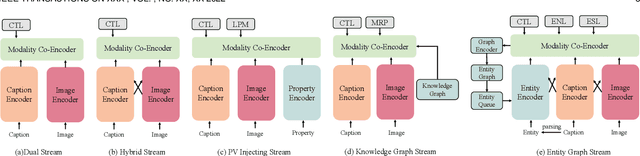
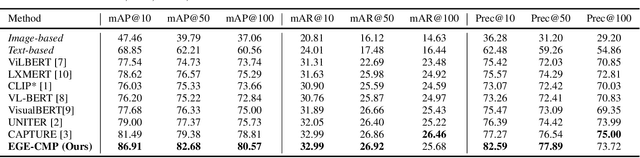
Our goal in this research is to study a more realistic environment in which we can conduct weakly-supervised multi-modal instance-level product retrieval for fine-grained product categories. We first contribute the Product1M datasets, and define two real practical instance-level retrieval tasks to enable the evaluations on the price comparison and personalized recommendations. For both instance-level tasks, how to accurately pinpoint the product target mentioned in the visual-linguistic data and effectively decrease the influence of irrelevant contents is quite challenging. To address this, we exploit to train a more effective cross-modal pertaining model which is adaptively capable of incorporating key concept information from the multi-modal data, by using an entity graph whose node and edge respectively denote the entity and the similarity relation between entities. Specifically, a novel Entity-Graph Enhanced Cross-Modal Pretraining (EGE-CMP) model is proposed for instance-level commodity retrieval, that explicitly injects entity knowledge in both node-based and subgraph-based ways into the multi-modal networks via a self-supervised hybrid-stream transformer, which could reduce the confusion between different object contents, thereby effectively guiding the network to focus on entities with real semantic. Experimental results well verify the efficacy and generalizability of our EGE-CMP, outperforming several SOTA cross-modal baselines like CLIP, UNITER and CAPTURE.