 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity-Graph Enhanced Cross-Modal Pretraining for Instance-level Product Retrieval
Jun 17, 2022

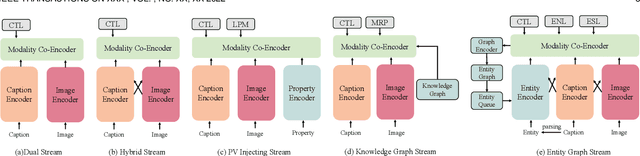
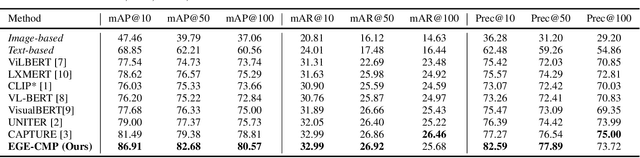
Our goal in this research is to study a more realistic environment in which we can conduct weakly-supervised multi-modal instance-level product retrieval for fine-grained product categories. We first contribute the Product1M datasets, and define two real practical instance-level retrieval tasks to enable the evaluations on the price comparison and personalized recommendations. For both instance-level tasks, how to accurately pinpoint the product target mentioned in the visual-linguistic data and effectively decrease the influence of irrelevant contents is quite challenging. To address this, we exploit to train a more effective cross-modal pertaining model which is adaptively capable of incorporating key concept information from the multi-modal data, by using an entity graph whose node and edge respectively denote the entity and the similarity relation between entities. Specifically, a novel Entity-Graph Enhanced Cross-Modal Pretraining (EGE-CMP) model is proposed for instance-level commodity retrieval, that explicitly injects entity knowledge in both node-based and subgraph-based ways into the multi-modal networks via a self-supervised hybrid-stream transformer, which could reduce the confusion between different object contents, thereby effectively guiding the network to focus on entities with real semantic. Experimental results well verify the efficacy and generalizability of our EGE-CMP, outperforming several SOTA cross-modal baselines like CLIP, UNITER and CAPTURE.
elBERto: Self-supervised Commonsense Learning for Question Answering
Mar 17, 2022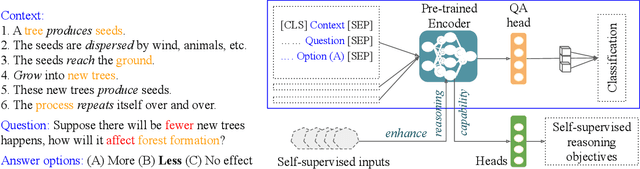

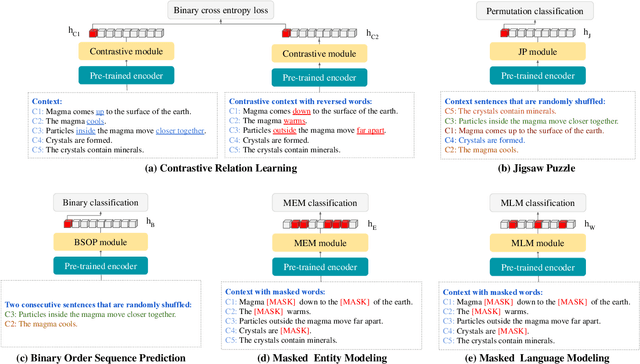
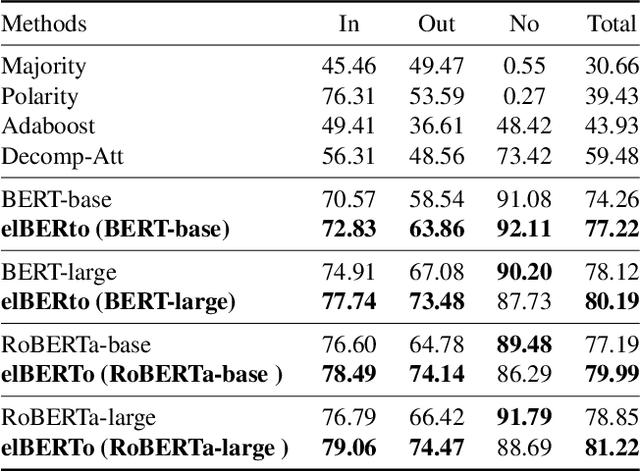
Commonsense question answering requires reasoning about everyday situations and causes and effects implicit in context. Typically, existing approaches first retrieve external evidence and then perform commonsense reasoning using these evidence. In this paper, we propose a Self-supervised Bidirectional Encoder Representation Learning of Commonsense (elBERto) framework, which is compatible with off-the-shelf QA model architectures. The framework comprises five self-supervised tasks to force the model to fully exploit the additional training signals from contexts containing rich commonsense. The tasks include a novel Contrastive Relation Learning task to encourage the model to distinguish between logically contrastive contexts, a new Jigsaw Puzzle task that requires the model to infer logical chains in long contexts, and three classic SSL tasks to maintain pre-trained models language encoding ability. On the representative WIQA, CosmosQA, and ReClor datasets, elBERto outperforms all other methods, including those utilizing explicit graph reasoning and external knowledge retrieval. Moreover, elBERto achieves substantial improvements on out-of-paragraph and no-effect questions where simple lexical similarity comparison does not help, indicating that it successfully learns commonsense and is able to leverage it when given dynamic context.
M5Product: A Multi-modal Pretraining Benchmark for E-commercial Product Downstream Tasks
Sep 09, 2021

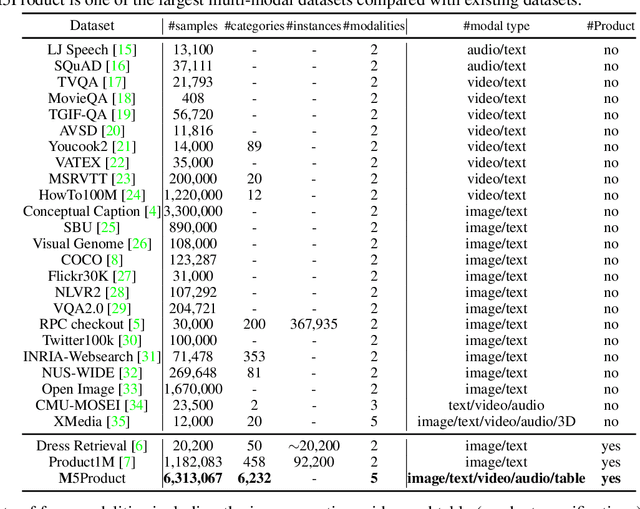

In this paper, we aim to advance the research of multi-modal pre-training on E-commerce and subsequently contribute a large-scale dataset, named M5Product, which consists of over 6 million multimodal pairs, covering more than 6,000 categories and 5,000 attributes. Generally, existing multi-modal datasets are either limited in scale or modality diversity. Differently, our M5Product is featured from the following aspects. First, the M5Product dataset is 500 times larger than the public multimodal dataset with the same number of modalities and nearly twice larger compared with the largest available text-image cross-modal dataset. Second, the dataset contains rich information of multiple modalities including image, text, table, video and audio, in which each modality can capture different views of semantic information (e.g. category, attributes, affordance, brand, preference) and complements the other. Third, to better accommodate with real-world problems, a few portion of M5Product contains incomplete modality pairs and noises while having the long-tailed distribution, which aligns well with real-world scenarios. Finally, we provide a baseline model M5-MMT that makes the first attempt to integrate the different modality configuration into an unified model for feature fusion to address the great challenge for semantic alignment. We also evaluate various multi-model pre-training state-of-the-arts for benchmarking their capabilities in learning from unlabeled data under the different number of modalities on the M5Product dataset. We conduct extensive experiments on four downstream tasks and provide some interesting findings on these modalities. Our dataset and related code are available at https://xiaodongsuper.github.io/M5Product_dataset.
Product1M: Towards Weakly Supervised Instance-Level Product Retrieval via Cross-modal Pretraining
Aug 09, 2021
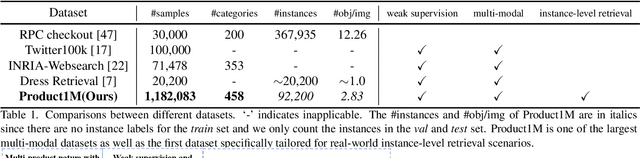
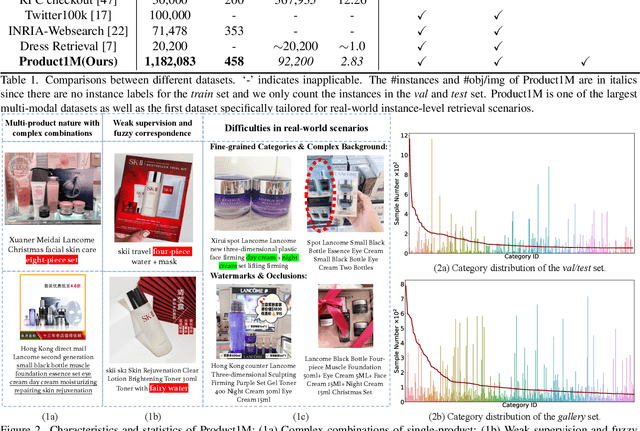
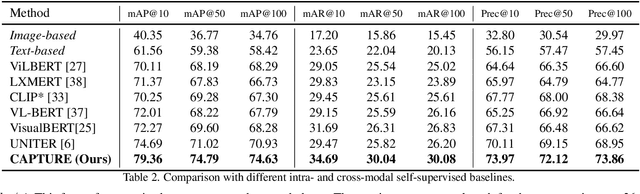
Nowadays, customer's demands for E-commerce are more diversified, which introduces more complications to the product retrieval industry. Previous methods are either subject to single-modal input or perform supervised image-level product retrieval, thus fail to accommodate real-life scenarios where enormous weakly annotated multi-modal data are present. In this paper, we investigate a more realistic setting that aims to perform weakly-supervised multi-modal instance-level product retrieval among fine-grained product categories. To promote the study of this challenging task, we contribute Product1M, one of the largest multi-modal cosmetic datasets for real-world instance-level retrieval. Notably, Product1M contains over 1 million image-caption pairs and consists of two sample types, i.e., single-product and multi-product samples, which encompass a wide variety of cosmetics brands. In addition to the great diversity, Product1M enjoys several appealing characteristics including fine-grained categories, complex combinations, and fuzzy correspondence that well mimic the real-world scenes. Moreover, we propose a novel model named Cross-modal contrAstive Product Transformer for instance-level prodUct REtrieval (CAPTURE), that excels in capturing the potential synergy between multi-modal inputs via a hybrid-stream transformer in a self-supervised manner.CAPTURE generates discriminative instance features via masked multi-modal learning as well as cross-modal contrastive pretraining and it outperforms several SOTA cross-modal baselines. Extensive ablation studies well demonstrate the effectiveness and the generalization capacity of our model. Dataset and codes are available at https: //github.com/zhanxlin/Product1M.
REM-Net: Recursive Erasure Memory Network for Commonsense Evidence Refinement
Jan 03, 2021
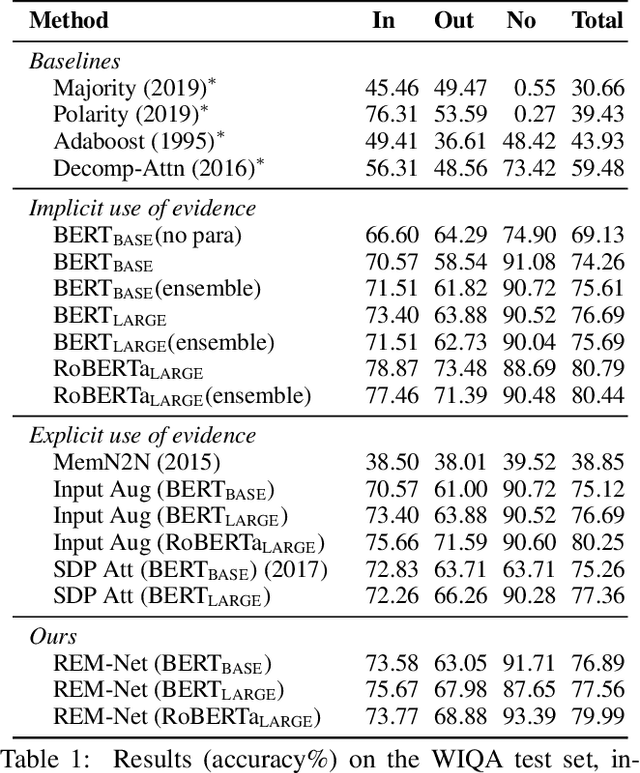
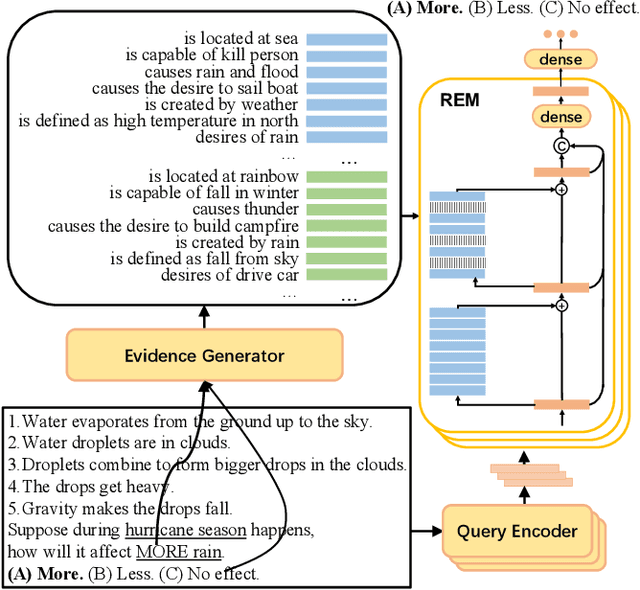

When answering a question, people often draw upon their rich world knowledge in addition to the particular context. While recent works retrieve supporting facts/evidence from commonsense knowledge bases to supply additional information to each question, there is still ample opportunity to advance it on the quality of the evidence. It is crucial since the quality of the evidence is the key to answering commonsense questions, and even determines the upper bound on the QA systems performance. In this paper, we propose a recursive erasure memory network (REM-Net) to cope with the quality improvement of evidence. To address this, REM-Net is equipped with a module to refine the evidence by recursively erasing the low-quality evidence that does not explain the question answering. Besides, instead of retrieving evidence from existing knowledge bases, REM-Net leverages a pre-trained generative model to generate candidate evidence customized for the question. We conduct experiments on two commonsense question answering datasets, WIQA and CosmosQA. The results demonstrate the performance of REM-Net and show that the refined evidence is explainable.