 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeelBERto: Self-supervised Commonsense Learning for Question Answering
Paper and Code
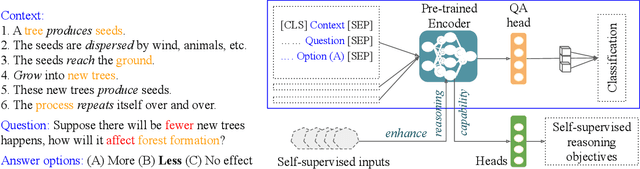

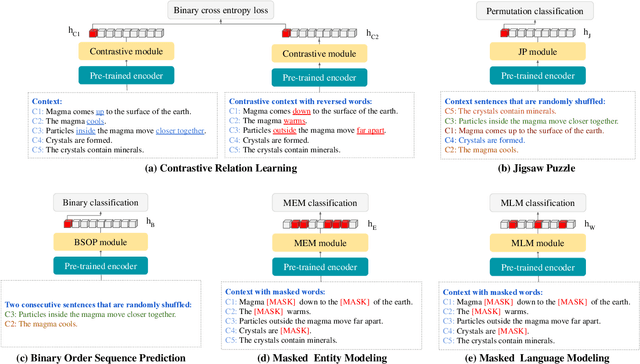
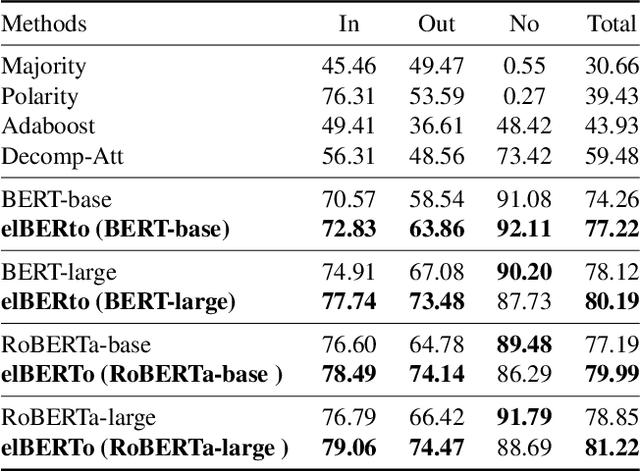
Commonsense question answering requires reasoning about everyday situations and causes and effects implicit in context. Typically, existing approaches first retrieve external evidence and then perform commonsense reasoning using these evidence. In this paper, we propose a Self-supervised Bidirectional Encoder Representation Learning of Commonsense (elBERto) framework, which is compatible with off-the-shelf QA model architectures. The framework comprises five self-supervised tasks to force the model to fully exploit the additional training signals from contexts containing rich commonsense. The tasks include a novel Contrastive Relation Learning task to encourage the model to distinguish between logically contrastive contexts, a new Jigsaw Puzzle task that requires the model to infer logical chains in long contexts, and three classic SSL tasks to maintain pre-trained models language encoding ability. On the representative WIQA, CosmosQA, and ReClor datasets, elBERto outperforms all other methods, including those utilizing explicit graph reasoning and external knowledge retrieval. Moreover, elBERto achieves substantial improvements on out-of-paragraph and no-effect questions where simple lexical similarity comparison does not help, indicating that it successfully learns commonsense and is able to leverage it when given dynamic context.