 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025



LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
Evo-MARL: Co-Evolutionary Multi-Agent Reinforcement Learning for Internalized Safety
Aug 05, 2025


Multi-agent systems (MAS) built on multimodal large language models exhibit strong collaboration and performance. However, their growing openness and interaction complexity pose serious risks, notably jailbreak and adversarial attacks. Existing defenses typically rely on external guard modules, such as dedicated safety agents, to handle unsafe behaviors. Unfortunately, this paradigm faces two challenges: (1) standalone agents offer limited protection, and (2) their independence leads to single-point failure-if compromised, system-wide safety collapses. Naively increasing the number of guard agents further raises cost and complexity. To address these challenges, we propose Evo-MARL, a novel multi-agent reinforcement learning (MARL) framework that enables all task agents to jointly acquire defensive capabilities. Rather than relying on external safety modules, Evo-MARL trains each agent to simultaneously perform its primary function and resist adversarial threats, ensuring robustness without increasing system overhead or single-node failure. Furthermore, Evo-MARL integrates evolutionary search with parameter-sharing reinforcement learning to co-evolve attackers and defenders. This adversarial training paradigm internalizes safety mechanisms and continually enhances MAS performance under co-evolving threats. Experiments show that Evo-MARL reduces attack success rates by up to 22% while boosting accuracy by up to 5% on reasoning tasks-demonstrating that safety and utility can be jointly improved.
Universal Approximation with Softmax Attention
Apr 22, 2025We prove that with linear transformations, both (i) two-layer self-attention and (ii) one-layer self-attention followed by a softmax function are universal approximators for continuous sequence-to-sequence functions on compact domains. Our main technique is a new interpolation-based method for analyzing attention's internal mechanism. This leads to our key insight: self-attention is able to approximate a generalized version of ReLU to arbitrary precision, and hence subsumes many known universal approximators. Building on these, we show that two-layer multi-head attention alone suffices as a sequence-to-sequence universal approximator. In contrast, prior works rely on feed-forward networks to establish universal approximation in Transformers. Furthermore, we extend our techniques to show that, (softmax-)attention-only layers are capable of approximating various statistical models in-context. We believe these techniques hold independent interest.
Transformers versus the EM Algorithm in Multi-class Clustering
Feb 09, 2025LLMs demonstrate significant inference capacities in complicated machine learning tasks, using the Transformer model as its backbone. Motivated by the limited understanding of such models on the unsupervised learning problems, we study the learning guarantees of Transformers in performing multi-class clustering of the Gaussian Mixture Models. We develop a theory drawing strong connections between the Softmax Attention layers and the workflow of the EM algorithm on clustering the mixture of Gaussians. Our theory provides approximation bounds for the Expectation and Maximization steps by proving the universal approximation abilities of multivariate mappings by Softmax functions. In addition to the approximation guarantees, we also show that with a sufficient number of pre-training samples and an initialization, Transformers can achieve the minimax optimal rate for the problem considered. Our extensive simulations empirically verified our theory by revealing the strong learning capacities of Transformers even beyond the assumptions in the theory, shedding light on the powerful inference capacities of LLMs.
Learning Spectral Methods by Transformers
Jan 05, 2025



Transformers demonstrate significant advantages as the building block of modern LLMs. In this work, we study the capacities of Transformers in performing unsupervised learning. We show that multi-layered Transformers, given a sufficiently large set of pre-training instances, are able to learn the algorithms themselves and perform statistical estimation tasks given new instances. This learning paradigm is distinct from the in-context learning setup and is similar to the learning procedure of human brains where skills are learned through past experience. Theoretically, we prove that pre-trained Transformers can learn the spectral methods and use the classification of bi-class Gaussian mixture model as an example. Our proof is constructive using algorithmic design techniques. Our results are built upon the similarities of multi-layered Transformer architecture with the iterative recovery algorithms used in practice. Empirically, we verify the strong capacity of the multi-layered (pre-trained) Transformer on unsupervised learning through the lens of both the PCA and the Clustering tasks performed on the synthetic and real-world datasets.
Transformers Simulate MLE for Sequence Generation in Bayesian Networks
Jan 05, 2025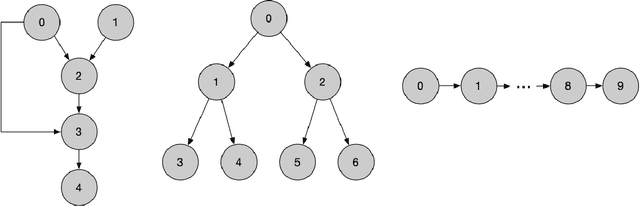

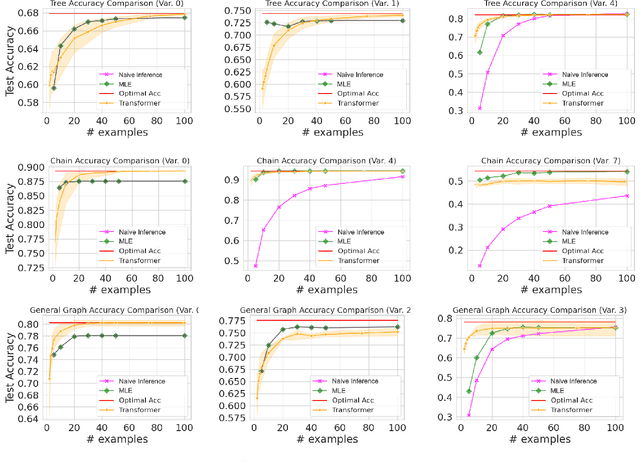
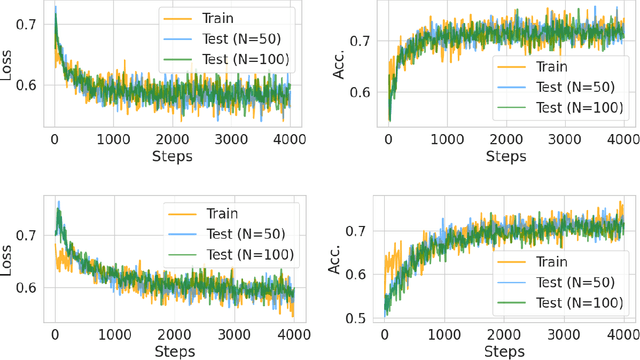
Transformers have achieved significant success in various fields, notably excelling in tasks involving sequential data like natural language processing. Despite these achievements, the theoretical understanding of transformers' capabilities remains limited. In this paper, we investigate the theoretical capabilities of transformers to autoregressively generate sequences in Bayesian networks based on in-context maximum likelihood estimation (MLE). Specifically, we consider a setting where a context is formed by a set of independent sequences generated according to a Bayesian network. We demonstrate that there exists a simple transformer model that can (i) estimate the conditional probabilities of the Bayesian network according to the context, and (ii) autoregressively generate a new sample according to the Bayesian network with estimated conditional probabilities. We further demonstrate in extensive experiments that such a transformer does not only exist in theory, but can also be effectively obtained through training. Our analysis highlights the potential of transformers to learn complex probabilistic models and contributes to a better understanding of large language models as a powerful class of sequence generators.
Outlier-Efficient Hopfield Layers for Large Transformer-Based Models
Apr 04, 2024



We introduce an Outlier-Efficient Modern Hopfield Model (termed $\mathtt{OutEffHop}$) and use it to address the outlier-induced challenge of quantizing gigantic transformer-based models. Our main contribution is a novel associative memory model facilitating \textit{outlier-efficient} associative memory retrievals. Interestingly, this memory model manifests a model-based interpretation of an outlier-efficient attention mechanism ($\text{Softmax}_1$): it is an approximation of the memory retrieval process of $\mathtt{OutEffHop}$. Methodologically, this allows us to debut novel outlier-efficient Hopfield layers a powerful attention alternative with superior post-quantization performance. Theoretically, the Outlier-Efficient Modern Hopfield Model retains and improves the desirable properties of the standard modern Hopfield models, including fixed point convergence and exponential storage capacity. Empirically, we demonstrate the proposed model's efficacy across large-scale transformer-based and Hopfield-based models (including BERT, OPT, ViT and STanHop-Net), benchmarking against state-of-the-art methods including $\mathtt{Clipped\_Softmax}$ and $\mathtt{Gated\_Attention}$. Notably, $\mathtt{OutEffHop}$ achieves on average $\sim$22+\% reductions in both average kurtosis and maximum infinity norm of model outputs accross 4 models.