 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterministic Differentiable Structured Pruning for Large Language Models
Mar 09, 2026Structured pruning reduces LLM inference cost by removing low-importance architectural components. This can be viewed as learning a multiplicative gate for each component under an l0 sparsity constraint. Due to the discreteness of the l0 norm, prior work typically adopts stochastic hard-concrete relaxations to enable differentiable optimization; however, this stochasticity can introduce a train--test mismatch when sampled masks are discretized for deployment and restricts masks to a bounded, near-binary range. To address this, we propose Deterministic Differentiable Pruning (DDP), a mask-only optimization method that eliminates stochasticity by directly optimizing a deterministic soft surrogate of the discrete l0 objective. Compared with prior approaches, DDP offers greater expressiveness, reduced train--test mismatch, and faster convergence. We apply our method to several dense and MoE models, including Qwen3-32B and Qwen3-30B-A3B, achieving a performance loss as small as 1% on downstream tasks while outperforming previous methods at 20% sparsity. We further demonstrate end-to-end inference speedups in realistic deployment settings with vLLM.
Pruning Large Language Models with Semi-Structural Adaptive Sparse Training
Jul 30, 2024Transformer-based Large Language Models (LLMs) have demonstrated remarkable success across various challenging tasks. However, the deployment of LLMs is hindered by their substantial parameter count and memory consumption. Recently, numerous studies have attempted to compress LLMs by pruning them using training-free methods. However, these pruned models often experience significant performance degradation on complex tasks. To address this issue, we propose a novel training pipeline for semi-structured sparse models, named Adaptive Sparse Trainer (AST). By distilling the knowledge stored in its dense counterpart, we prevent the sparse model from overfitting and ensure a stable training process. Moreover, AST allows the model to adaptively select better lottery tickets (e.g., masks) during training. Additionally, we discovered that adding extra well-initialized parameters can further enhance model performance with only a small increase in memory footprint. Our method significantly narrows the performance gap between dense and sparse models while maintaining limited computational cost. Furthermore, when combined with existing quantization methods, AST can compress language models by up to 16x compared to dense FP32 precision models with minimal performance loss. AST outperforms previous state-of-the-art methods by reducing the zero-shot accuracy gap between dense and semi-structured sparse models to 1.12% across multiple zero-shot tasks on Llama2-7B, using less than 0.4% of the pretraining tokens.
Accelerating Transformer Pre-Training with 2:4 Sparsity
Apr 02, 2024Training large Transformers is slow, but recent innovations on GPU architecture gives us an advantage. NVIDIA Ampere GPUs can execute a fine-grained 2:4 sparse matrix multiplication twice as fast as its dense equivalent. In the light of this property, we comprehensively investigate the feasibility of accelerating feed-forward networks (FFNs) of Transformers in pre-training. First, we define a "flip rate" to monitor the stability of a 2:4 training process. Utilizing this metric, we suggest two techniques to preserve accuracy: to modify the sparse-refined straight-through estimator by applying the mask decay term on gradients, and to enhance the model's quality by a simple yet effective dense fine-tuning procedure near the end of pre-training. Besides, we devise two effective techniques to practically accelerate training: to calculate transposable 2:4 mask by convolution, and to accelerate gated activation functions by reducing GPU L2 cache miss. Experiments show that a combination of our methods reaches the best performance on multiple Transformers among different 2:4 training methods, while actual acceleration can be observed on different shapes of Transformer block.
Modeling Treatment Delays for Patients using Feature Label Pairs in a Time Series
Dec 03, 2018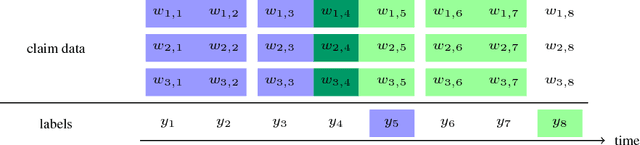
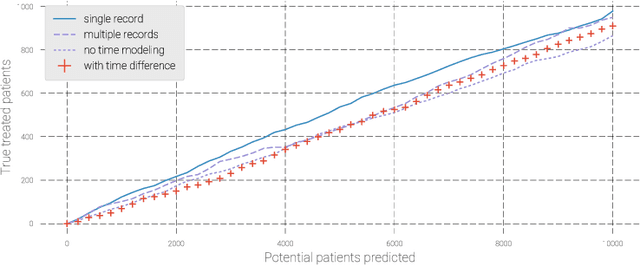
Pharmaceutical targeting is one of key inputs for making sales and marketing strategy planning. Targeting list is built on predicting physician's sales potential of certain type of patient. In this paper, we present a time-sensitive targeting framework leveraging time series model to predict patient's disease and treatment progression. We create time features by extracting service history within a certain period, and record whether the event happens in a look-forward period. Such feature-label pairs are examined across all time periods and all patients to train a model. It keeps the inherent order of services and evaluates features associated to the imminent future, which contribute to improved accuracy.