 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Semantics to Pixels: Coarse-to-Fine Masked Autoencoders for Hierarchical Visual Understanding
Mar 10, 2026Self-supervised visual pre-training methods face an inherent tension: contrastive learning (CL) captures global semantics but loses fine-grained detail, while masked image modeling (MIM) preserves local textures but suffers from "attention drift" due to semantically-agnostic random masking. We propose C2FMAE, a coarse-to-fine masked autoencoder that resolves this tension by explicitly learning hierarchical visual representations across three data granularities: semantic masks (scene-level), instance masks (object-level), and RGB images (pixel-level). Two synergistic innovations enforce a strict top-down learning principle. First, a cascaded decoder sequentially reconstructs from scene semantics to object instances to pixel details, establishing explicit cross-granularity dependencies that parallel decoders cannot capture. Second, a progressive masking curriculum dynamically shifts the training focus from semantic-guided to instance-guided and finally to random masking, creating a structured learning path from global context to local features. To support this framework, we construct a large-scale multi-granular dataset with high-quality pseudo-labels for all 1.28M ImageNet-1K images. Extensive experiments show that C2FMAE achieves significant performance gains on image classification, object detection, and semantic segmentation, validating the effectiveness of our hierarchical design in learning more robust and generalizable representations.
AEMIM: Adversarial Examples Meet Masked Image Modeling
Jul 16, 2024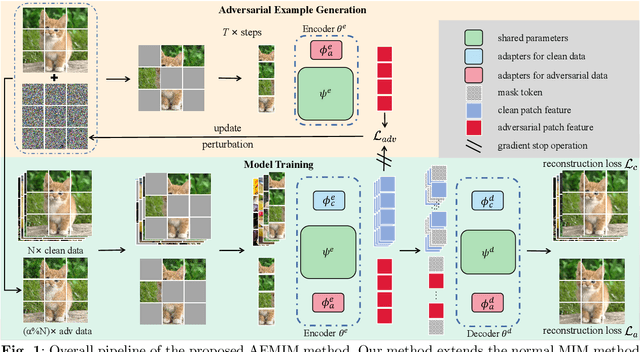


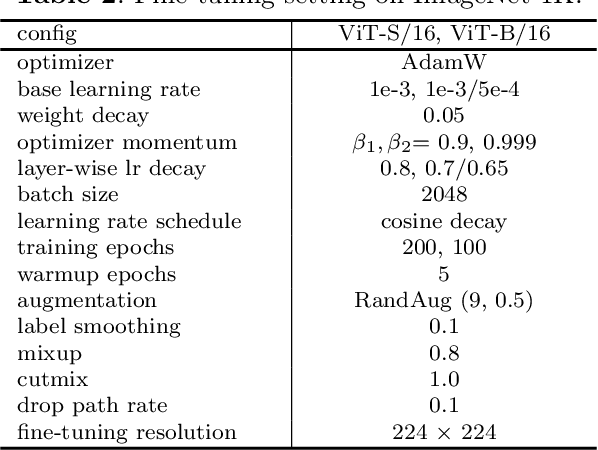
Masked image modeling (MIM) has gained significant traction for its remarkable prowess in representation learning. As an alternative to the traditional approach, the reconstruction from corrupted images has recently emerged as a promising pretext task. However, the regular corrupted images are generated using generic generators, often lacking relevance to the specific reconstruction task involved in pre-training. Hence, reconstruction from regular corrupted images cannot ensure the difficulty of the pretext task, potentially leading to a performance decline. Moreover, generating corrupted images might introduce an extra generator, resulting in a notable computational burden. To address these issues, we propose to incorporate adversarial examples into masked image modeling, as the new reconstruction targets. Adversarial examples, generated online using only the trained models, can directly aim to disrupt tasks associated with pre-training. Therefore, the incorporation not only elevates the level of challenge in reconstruction but also enhances efficiency, contributing to the acquisition of superior representations by the model. In particular, we introduce a novel auxiliary pretext task that reconstructs the adversarial examples corresponding to the original images. We also devise an innovative adversarial attack to craft more suitable adversarial examples for MIM pre-training. It is noted that our method is not restricted to specific model architectures and MIM strategies, rendering it an adaptable plug-in capable of enhancing all MIM methods. Experimental findings substantiate the remarkable capability of our approach in amplifying the generalization and robustness of existing MIM methods. Notably, our method surpasses the performance of baselines on various tasks, including ImageNet, its variants, and other downstream tasks.
The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking
Mar 26, 2018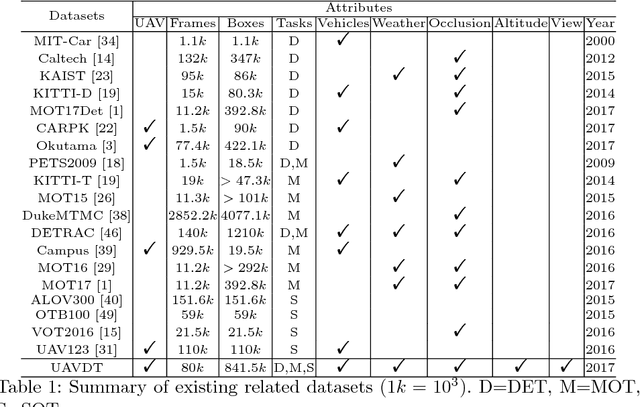
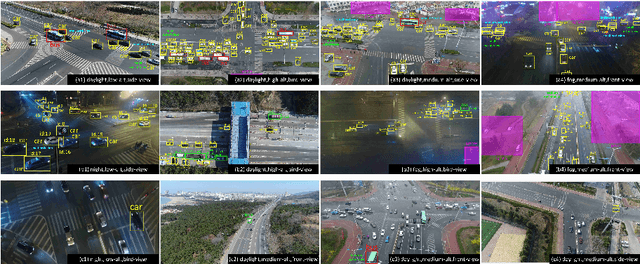
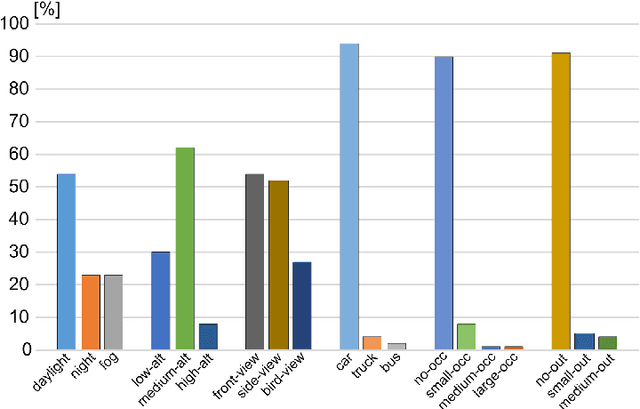
With the advantage of high mobility, Unmanned Aerial Vehicles (UAVs) are used to fuel numerous important applications in computer vision, delivering more efficiency and convenience than surveillance cameras with fixed camera angle, scale and view. However, very limited UAV datasets are proposed, and they focus only on a specific task such as visual tracking or object detection in relatively constrained scenarios. Consequently, it is of great importance to develop an unconstrained UAV benchmark to boost related researches. In this paper, we construct a new UAV benchmark focusing on complex scenarios with new level challenges. Selected from 10 hours raw videos, about 80,000 representative frames are fully annotated with bounding boxes as well as up to 14 kinds of attributes (e.g., weather condition, flying altitude, camera view, vehicle category, and occlusion) for three fundamental computer vision tasks: object detection, single object tracking, and multiple object tracking. Then, a detailed quantitative study is performed using most recent state-of-the-art algorithms for each task. Experimental results show that the current state-of-the-art methods perform relative worse on our dataset, due to the new challenges appeared in UAV based real scenes, e.g., high density, small object, and camera motion. To our knowledge, our work is the first time to explore such issues in unconstrained scenes comprehensively.