 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenterNet++ for Object Detection
Apr 18, 2022

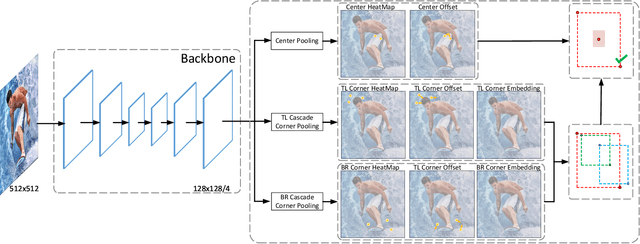
There are two mainstreams for object detection: top-down and bottom-up. The state-of-the-art approaches mostly belong to the first category. In this paper, we demonstrate that the bottom-up approaches are as competitive as the top-down and enjoy higher recall. Our approach, named CenterNet, detects each object as a triplet keypoints (top-left and bottom-right corners and the center keypoint). We firstly group the corners by some designed cues and further confirm the objects by the center keypoints. The corner keypoints equip the approach with the ability to detect objects of various scales and shapes and the center keypoint avoids the confusion brought by a large number of false-positive proposals. Our approach is a kind of anchor-free detector because it does not need to define explicit anchor boxes. We adapt our approach to the backbones with different structures, i.e., the 'hourglass' like networks and the the 'pyramid' like networks, which detect objects on a single-resolution feature map and multi-resolution feature maps, respectively. On the MS-COCO dataset, CenterNet with Res2Net-101 and Swin-Transformer achieves APs of 53.7% and 57.1%, respectively, outperforming all existing bottom-up detectors and achieving state-of-the-art. We also design a real-time CenterNet, which achieves a good trade-off between accuracy and speed with an AP of 43.6% at 30.5 FPS. https://github.com/Duankaiwen/PyCenterNet.
Location-Sensitive Visual Recognition with Cross-IOU Loss
Apr 11, 2021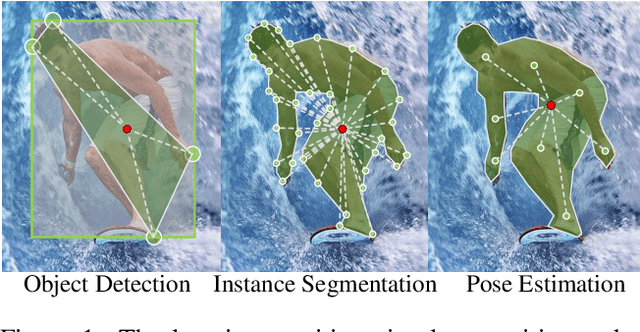



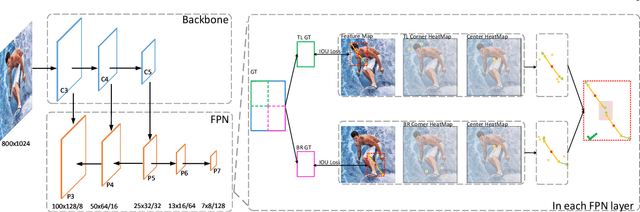
Object detection, instance segmentation, and pose estimation are popular visual recognition tasks which require localizing the object by internal or boundary landmarks. This paper summarizes these tasks as location-sensitive visual recognition and proposes a unified solution named location-sensitive network (LSNet). Based on a deep neural network as the backbone, LSNet predicts an anchor point and a set of landmarks which together define the shape of the target object. The key to optimizing the LSNet lies in the ability of fitting various scales, for which we design a novel loss function named cross-IOU loss that computes the cross-IOU of each anchor point-landmark pair to approximate the global IOU between the prediction and ground-truth. The flexibly located and accurately predicted landmarks also enable LSNet to incorporate richer contextual information for visual recognition. Evaluated on the MS-COCO dataset, LSNet set the new state-of-the-art accuracy for anchor-free object detection (a 53.5% box AP) and instance segmentation (a 40.2% mask AP), and shows promising performance in detecting multi-scale human poses. Code is available at https://github.com/Duankaiwen/LSNet
Corner Proposal Network for Anchor-free, Two-stage Object Detection
Jul 27, 2020
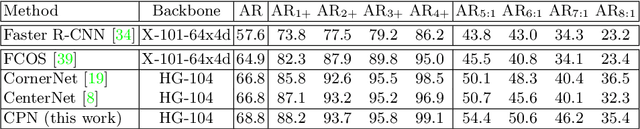

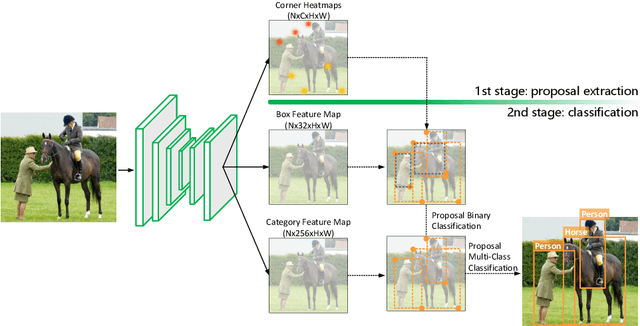
The goal of object detection is to determine the class and location of objects in an image. This paper proposes a novel anchor-free, two-stage framework which first extracts a number of object proposals by finding potential corner keypoint combinations and then assigns a class label to each proposal by a standalone classification stage. We demonstrate that these two stages are effective solutions for improving recall and precision, respectively, and they can be integrated into an end-to-end network. Our approach, dubbed Corner Proposal Network (CPN), enjoys the ability to detect objects of various scales and also avoids being confused by a large number of false-positive proposals. On the MS-COCO dataset, CPN achieves an AP of 49.2% which is competitive among state-of-the-art object detection methods. CPN also fits the scenario of computational efficiency, which achieves an AP of 41.6%/39.7% at 26.2/43.3 FPS, surpassing most competitors with the same inference speed. Code is available at https://github.com/Duankaiwen/CPNDet
CenterNet: Keypoint Triplets for Object Detection
Apr 19, 2019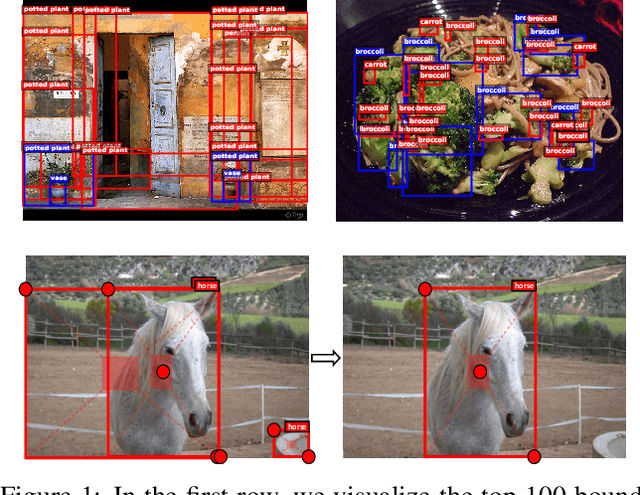
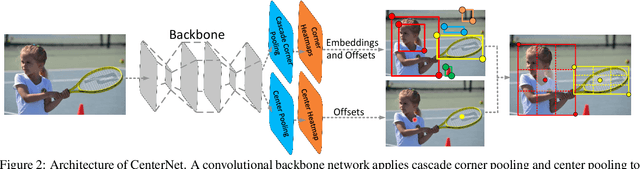
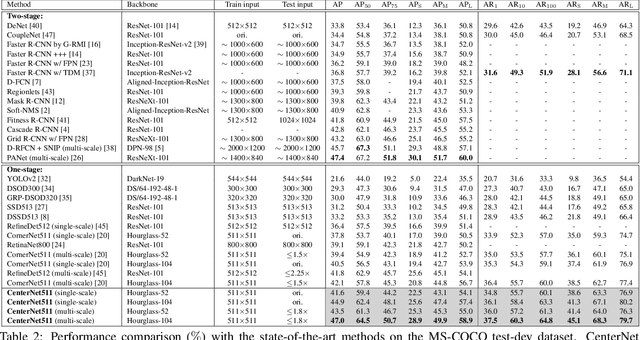
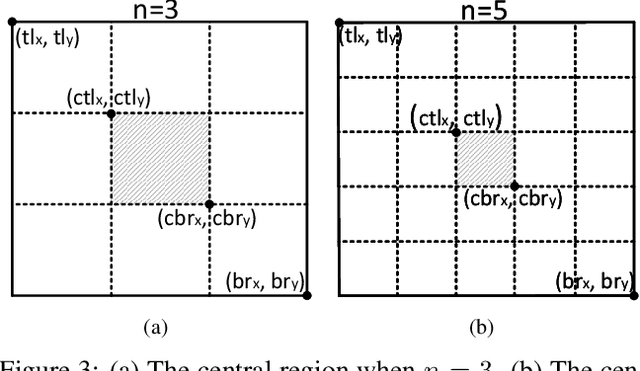
In object detection, keypoint-based approaches often suffer a large number of incorrect object bounding boxes, arguably due to the lack of an additional look into the cropped regions. This paper presents an efficient solution which explores the visual patterns within each cropped region with minimal costs. We build our framework upon a representative one-stage keypoint-based detector named CornerNet. Our approach, named CenterNet, detects each object as a triplet, rather than a pair, of keypoints, which improves both precision and recall. Accordingly, we design two customized modules named cascade corner pooling and center pooling, which play the roles of enriching information collected by both top-left and bottom-right corners and providing more recognizable information at the central regions, respectively. On the MS-COCO dataset, CenterNet achieves an AP of 47.0%, which outperforms all existing one-stage detectors by at least 4.9%. Meanwhile, with a faster inference speed, CenterNet demonstrates quite comparable performance to the top-ranked two-stage detectors. Code is available at https://github.com/Duankaiwen/CenterNet.
The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking
Mar 26, 2018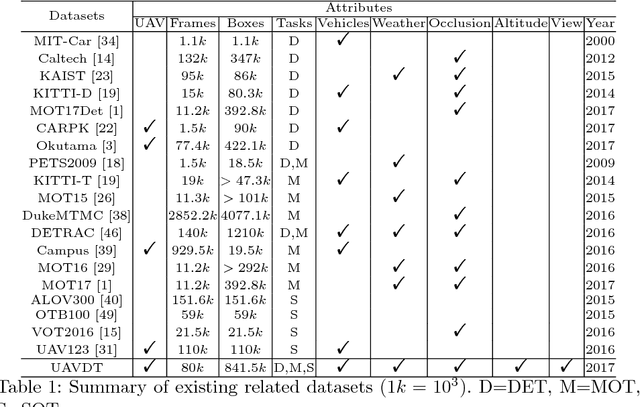
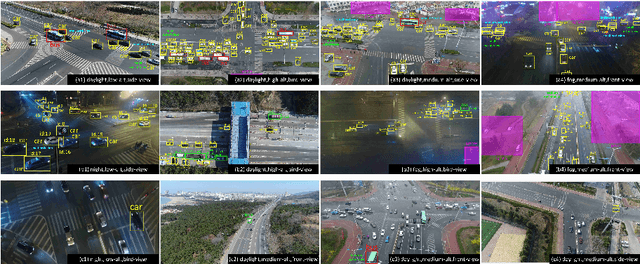
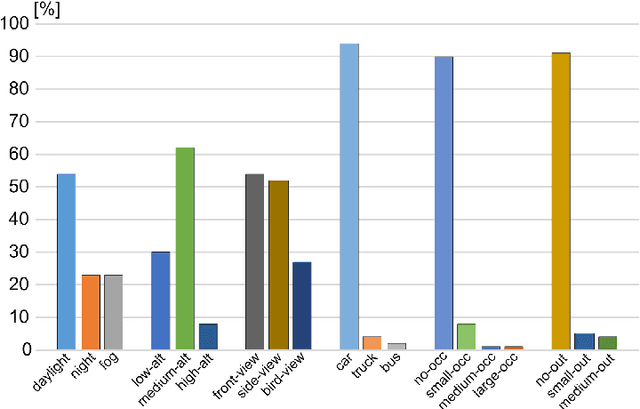
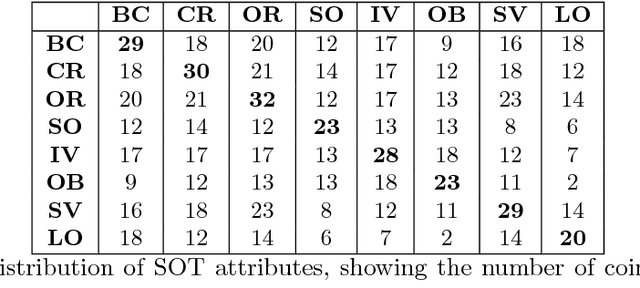
With the advantage of high mobility, Unmanned Aerial Vehicles (UAVs) are used to fuel numerous important applications in computer vision, delivering more efficiency and convenience than surveillance cameras with fixed camera angle, scale and view. However, very limited UAV datasets are proposed, and they focus only on a specific task such as visual tracking or object detection in relatively constrained scenarios. Consequently, it is of great importance to develop an unconstrained UAV benchmark to boost related researches. In this paper, we construct a new UAV benchmark focusing on complex scenarios with new level challenges. Selected from 10 hours raw videos, about 80,000 representative frames are fully annotated with bounding boxes as well as up to 14 kinds of attributes (e.g., weather condition, flying altitude, camera view, vehicle category, and occlusion) for three fundamental computer vision tasks: object detection, single object tracking, and multiple object tracking. Then, a detailed quantitative study is performed using most recent state-of-the-art algorithms for each task. Experimental results show that the current state-of-the-art methods perform relative worse on our dataset, due to the new challenges appeared in UAV based real scenes, e.g., high density, small object, and camera motion. To our knowledge, our work is the first time to explore such issues in unconstrained scenes comprehensively.