 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Cannot Easily Catch Me: A Low-Detectable Adversarial Patch for Object Detectors
Paper and Code
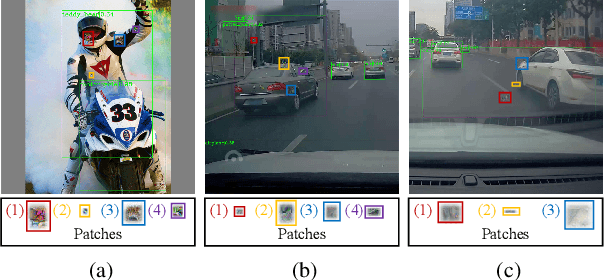
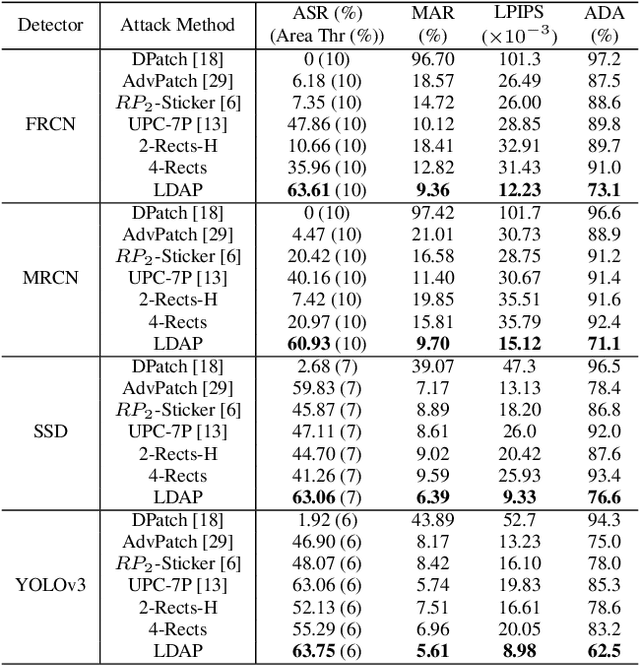
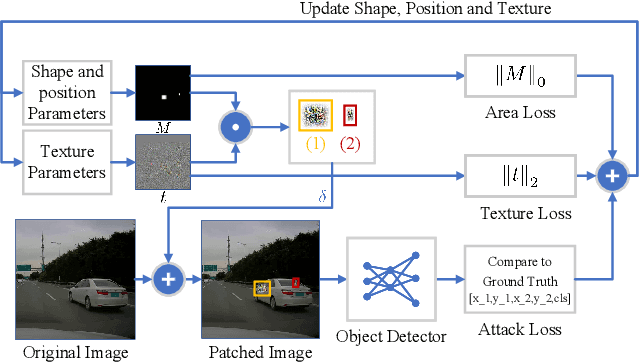

Blind spots or outright deceit can bedevil and deceive machine learning models. Unidentified objects such as digital "stickers," also known as adversarial patches, can fool facial recognition systems, surveillance systems and self-driving cars. Fortunately, most existing adversarial patches can be outwitted, disabled and rejected by a simple classification network called an adversarial patch detector, which distinguishes adversarial patches from original images. An object detector classifies and predicts the types of objects within an image, such as by distinguishing a motorcyclist from the motorcycle, while also localizing each object's placement within the image by "drawing" so-called bounding boxes around each object, once again separating the motorcyclist from the motorcycle. To train detectors even better, however, we need to keep subjecting them to confusing or deceitful adversarial patches as we probe for the models' blind spots. For such probes, we came up with a novel approach, a Low-Detectable Adversarial Patch, which attacks an object detector with small and texture-consistent adversarial patches, making these adversaries less likely to be recognized. Concretely, we use several geometric primitives to model the shapes and positions of the patches. To enhance our attack performance, we also assign different weights to the bounding boxes in terms of loss function. Our experiments on the common detection dataset COCO as well as the driving-video dataset D2-City show that LDAP is an effective attack method, and can resist the adversarial patch detector.