Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Fast and Accurate Neural Chinese Word Segmentation with Multi-Criteria Learning
Paper and Code
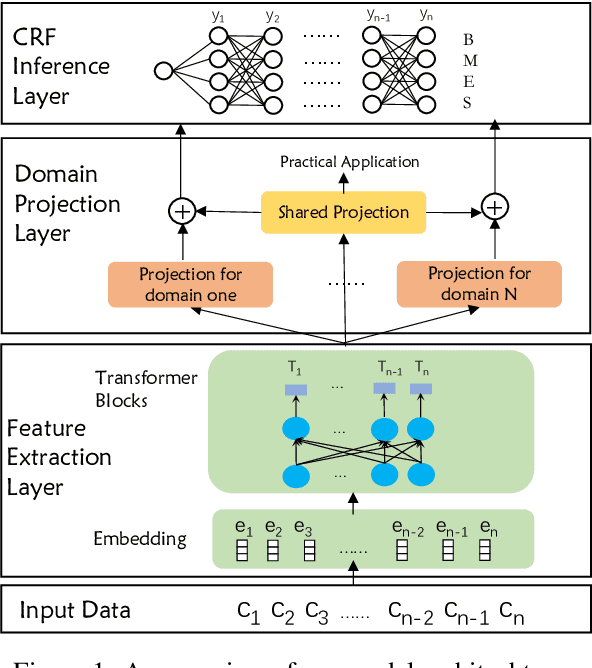
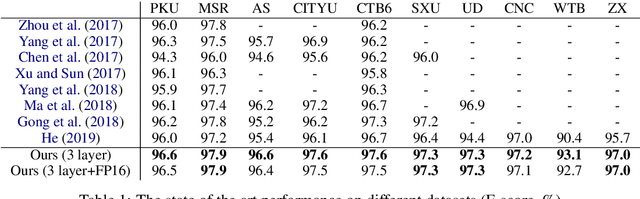
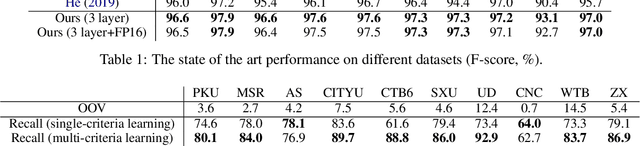
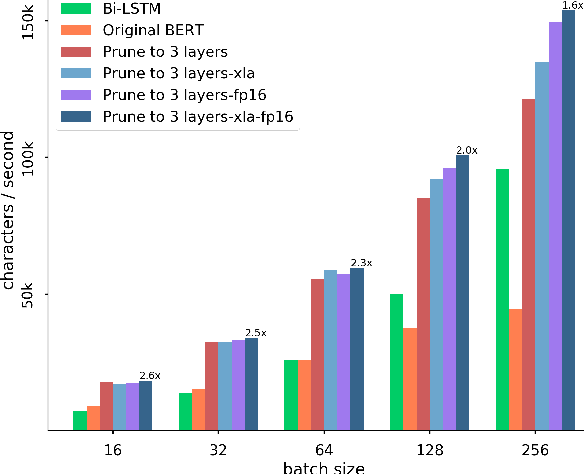
The ambiguous annotation criteria bring into the divergence of Chinese Word Segmentation (CWS) datasets with various granularities. Multi-criteria learning leverage the annotation style of individual datasets and mine their common basic knowledge. In this paper, we proposed a domain adaptive segmenter to capture diverse criteria of datasets. Our model is based on Bidirectional Encoder Representations from Transformers (BERT), which is responsible for introducing external knowledge. We also optimize its computational efficiency via model pruning, quantization, and compiler optimization. Experiments show that our segmenter outperforms the previous results on 10 CWS datasets and is faster than the previous state-of-the-art Bi-LSTM-CRF model.
View paper on