 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-complexity Joint Phase Adjustment and Receive Beamforming for Directional Modulation Networks via IRS
Jul 11, 2022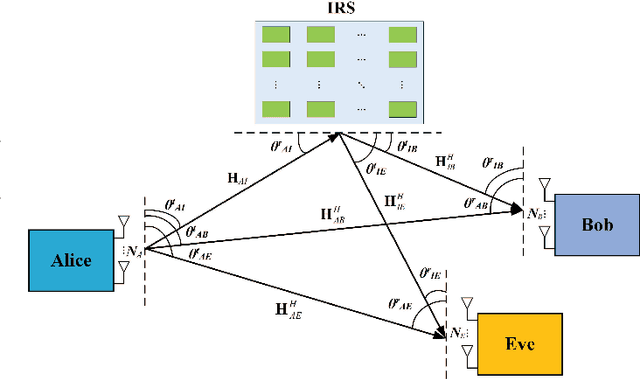
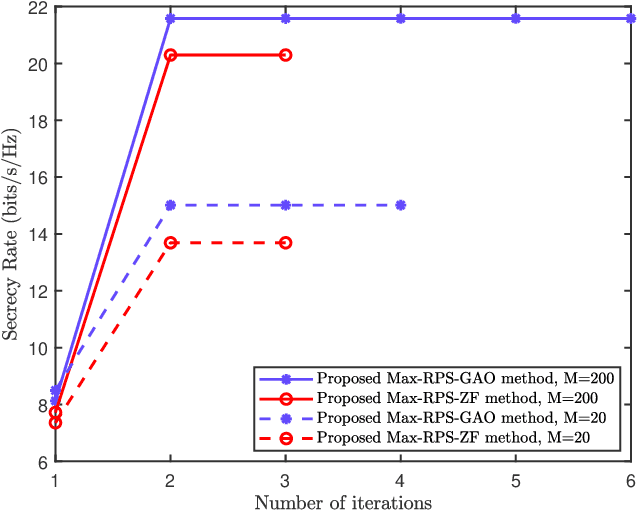
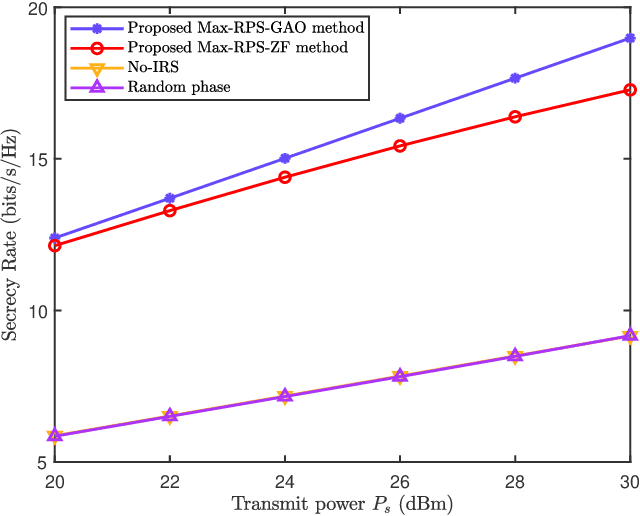
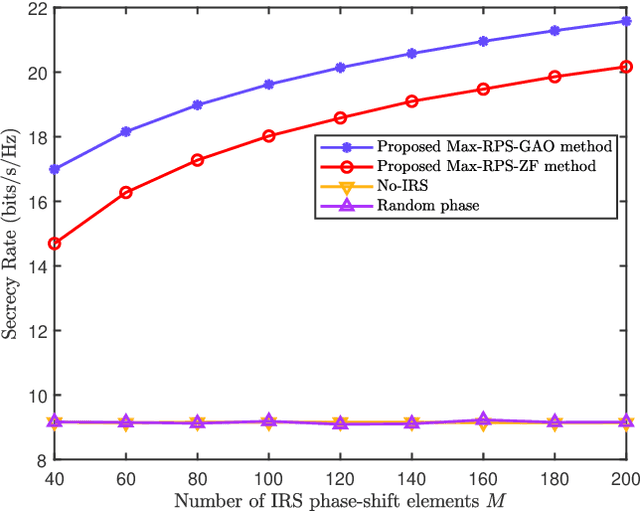
Intelligent reflecting surface (IRS) is a revolutionary and low-cost technology for boosting the spectrum and energy efficiencies in future wireless communication network. In order to create controllable multipath transmission in the conventional line-of-sight (LOS) wireless communication environment, an IRS-aided directional modulation (DM) network is considered. In this paper, to improve the transmission security of the system and maximize the receive power sum (Max-RPS), two alternately optimizing schemes of jointly designing receive beamforming (RBF) vectors and IRS phase shift matrix (PSM) are proposed: Max-RPS using general alternating optimization (Max-RPS-GAO) algorithm and Max-RPS using zero-forcing (Max-RPS-ZF) algorithm. Simulation results show that, compared with the no-IRS-assisted scheme and the no-PSM optimization scheme, the proposed IRS-assisted Max-RPS-GAO method and Max-RPS-ZF method can significantly improve the secrecy rate (SR) performance of the DM system. Moreover, compared with the Max-RPS-GAO method, the proposed Max-RPS-ZF method has a faster convergence speed and a certain lower computational complexity.
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
May 13, 2020
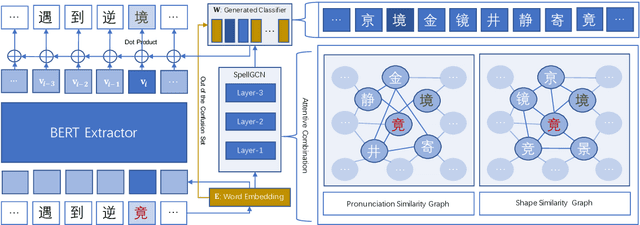
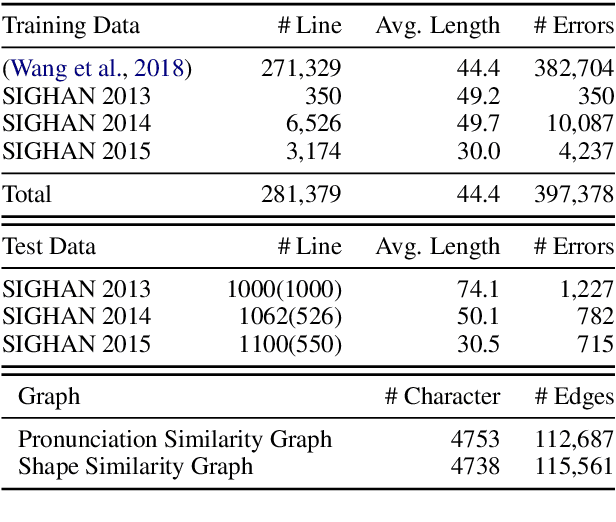
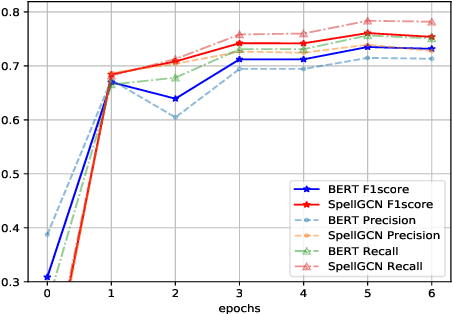
Chinese Spelling Check (CSC) is a task to detect and correct spelling errors in Chinese natural language. Existing methods have made attempts to incorporate the similarity knowledge between Chinese characters. However, they take the similarity knowledge as either an external input resource or just heuristic rules. This paper proposes to incorporate phonological and visual similarity knowledge into language models for CSC via a specialized graph convolutional network (SpellGCN). The model builds a graph over the characters, and SpellGCN is learned to map this graph into a set of inter-dependent character classifiers. These classifiers are applied to the representations extracted by another network, such as BERT, enabling the whole network to be end-to-end trainable. Experiments (The dataset and all code for this paper are available at https://github.com/ACL2020SpellGCN/SpellGCN) are conducted on three human-annotated datasets. Our method achieves superior performance against previous models by a large margin.
Neural Model-Based Reinforcement Learning for Recommendation
Dec 27, 2018

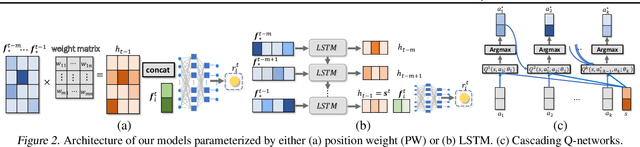
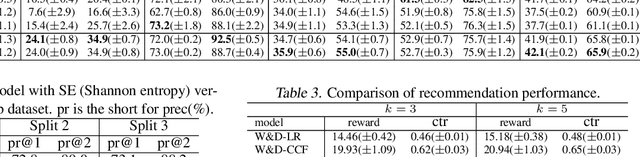
There are great interests as well as many challenges in applying reinforcement learning (RL) to recommendation systems. In this setting, an online user is the environment; neither the reward function nor the environment dynamics are clearly defined, making the application of RL challenging. In this paper, we propose a novel model-based reinforcement learning framework for recommendation systems, where we develop a generative adversarial network to imitate user behavior dynamics and learn her reward function. Using this user model as the simulation environment, we develop a novel DQN algorithm to obtain a combinatorial recommendation policy which can handle a large number of candidate items efficiently. In our experiments with real data, we show this generative adversarial user model can better explain user behavior than alternatives, and the RL policy based on this model can lead to a better long-term reward for the user and higher click rate for the system.