 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRescriber: Smaller-LLM-Powered User-Led Data Minimization for Navigating Privacy Trade-offs in LLM-Based Conversational Agent
Oct 10, 2024



The proliferation of LLM-based conversational agents has resulted in excessive disclosure of identifiable or sensitive information. However, existing technologies fail to offer perceptible control or account for users' personal preferences about privacy-utility tradeoffs due to the lack of user involvement. To bridge this gap, we designed, built, and evaluated Rescriber, a browser extension that supports user-led data minimization in LLM-based conversational agents by helping users detect and sanitize personal information in their prompts. Our studies (N=12) showed that Rescriber helped users reduce unnecessary disclosure and addressed their privacy concerns. Users' subjective perceptions of the system powered by Llama3-8B were on par with that by GPT-4. The comprehensiveness and consistency of the detection and sanitization emerge as essential factors that affect users' trust and perceived protection. Our findings confirm the viability of smaller-LLM-powered, user-facing, on-device privacy controls, presenting a promising approach to address the privacy and trust challenges of AI.
From Denoising Training to Test-Time Adaptation: Enhancing Domain Generalization for Medical Image Segmentation
Nov 03, 2023In medical image segmentation, domain generalization poses a significant challenge due to domain shifts caused by variations in data acquisition devices and other factors. These shifts are particularly pronounced in the most common scenario, which involves only single-source domain data due to privacy concerns. To address this, we draw inspiration from the self-supervised learning paradigm that effectively discourages overfitting to the source domain. We propose the Denoising Y-Net (DeY-Net), a novel approach incorporating an auxiliary denoising decoder into the basic U-Net architecture. The auxiliary decoder aims to perform denoising training, augmenting the domain-invariant representation that facilitates domain generalization. Furthermore, this paradigm provides the potential to utilize unlabeled data. Building upon denoising training, we propose Denoising Test Time Adaptation (DeTTA) that further: (i) adapts the model to the target domain in a sample-wise manner, and (ii) adapts to the noise-corrupted input. Extensive experiments conducted on widely-adopted liver segmentation benchmarks demonstrate significant domain generalization improvements over our baseline and state-of-the-art results compared to other methods. Code is available at https://github.com/WenRuxue/DeTTA.
CORGI-PM: A Chinese Corpus For Gender Bias Probing and Mitigation
Jan 01, 2023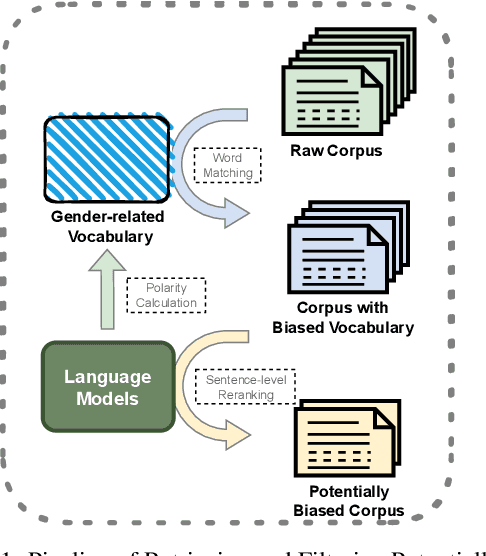
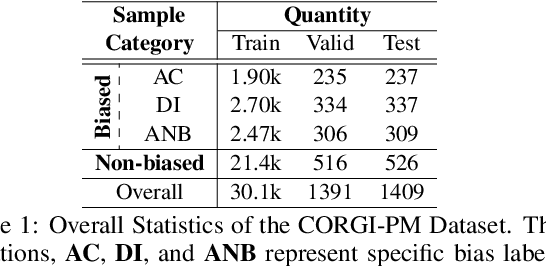
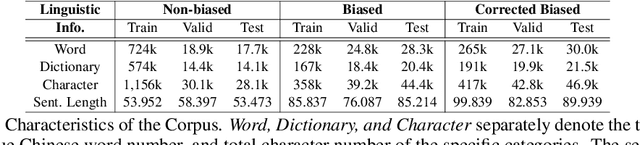
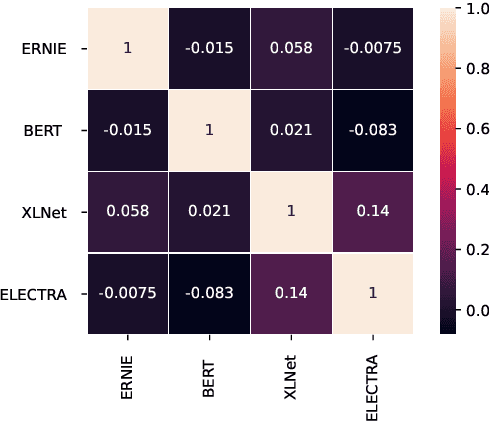
As natural language processing (NLP) for gender bias becomes a significant interdisciplinary topic, the prevalent data-driven techniques such as large-scale language models suffer from data inadequacy and biased corpus, especially for languages with insufficient resources such as Chinese. To this end, we propose a Chinese cOrpus foR Gender bIas Probing and Mitigation CORGI-PM, which contains 32.9k sentences with high-quality labels derived by following an annotation scheme specifically developed for gender bias in the Chinese context. Moreover, we address three challenges for automatic textual gender bias mitigation, which requires the models to detect, classify, and mitigate textual gender bias. We also conduct experiments with state-of-the-art language models to provide baselines. To our best knowledge, CORGI-PM is the first sentence-level Chinese corpus for gender bias probing and mitigation.