 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating The Risk of Imbalanced Datasets in Chest X-ray Image-based Diagnostics by Prototypical Relevance Propagation
Paper and Code
Jan 10, 2022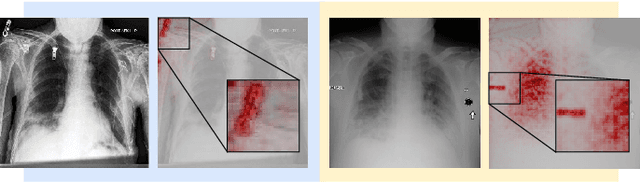

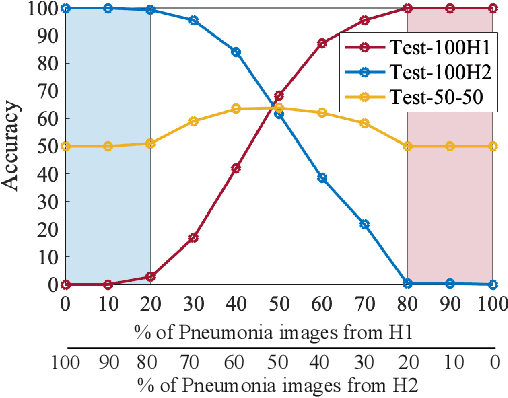

The recent trend of integrating multi-source Chest X-Ray datasets to improve automated diagnostics raises concerns that models learn to exploit source-specific correlations to improve performance by recognizing the source domain of an image rather than the medical pathology. We hypothesize that this effect is enforced by and leverages label-imbalance across the source domains, i.e, prevalence of a disease corresponding to a source. Therefore, in this work, we perform a thorough study of the effect of label-imbalance in multi-source training for the task of pneumonia detection on the widely used ChestX-ray14 and CheXpert datasets. The results highlight and stress the importance of using more faithful and transparent self-explaining models for automated diagnosis, thus enabling the inherent detection of spurious learning. They further illustrate that this undesirable effect of learning spurious correlations can be reduced considerably when ensuring label-balanced source domain datasets.