 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThis looks more like that: Enhancing Self-Explaining Models by Prototypical Relevance Propagation
Paper and Code
Aug 27, 2021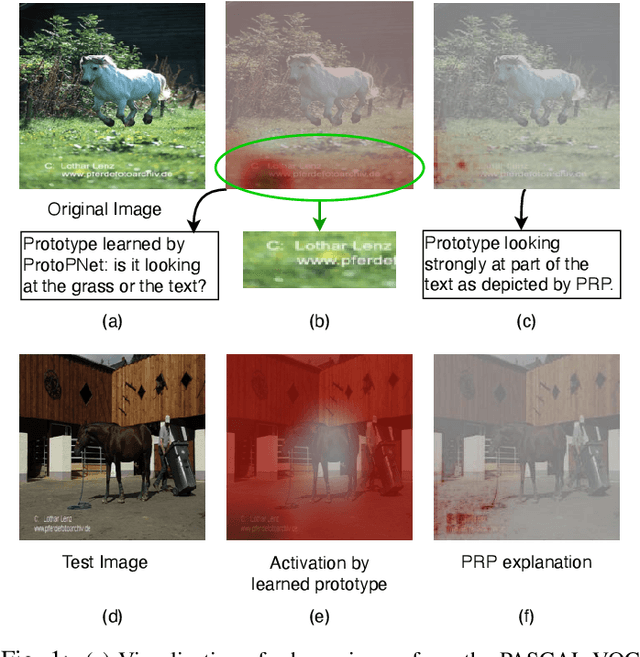
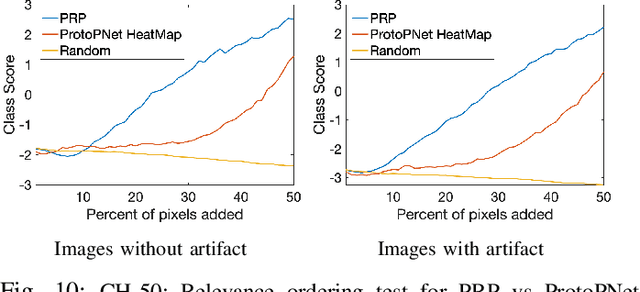

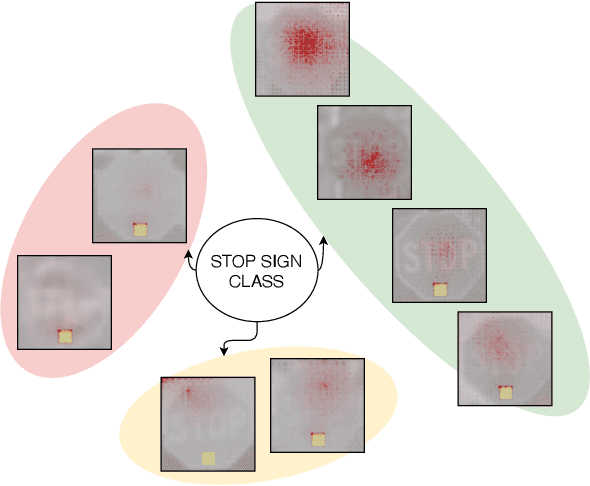
Current machine learning models have shown high efficiency in solving a wide variety of real-world problems. However, their black box character poses a major challenge for the understanding and traceability of the underlying decision-making strategies. As a remedy, many post-hoc explanation and self-explanatory methods have been developed to interpret the models' behavior. These methods, in addition, enable the identification of artifacts that can be learned by the model as class-relevant features. In this work, we provide a detailed case study of the self-explaining network, ProtoPNet, in the presence of a spectrum of artifacts. Accordingly, we identify the main drawbacks of ProtoPNet, especially, its coarse and spatially imprecise explanations. We address these limitations by introducing Prototypical Relevance Propagation (PRP), a novel method for generating more precise model-aware explanations. Furthermore, in order to obtain a clean dataset, we propose to use multi-view clustering strategies for segregating the artifact images using the PRP explanations, thereby suppressing the potential artifact learning in the models.