 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaultDiffusion: Few-Shot Fault Time Series Generation with Diffusion Model
Nov 19, 2025In industrial equipment monitoring, fault diagnosis is critical for ensuring system reliability and enabling predictive maintenance. However, the scarcity of fault data, due to the rarity of fault events and the high cost of data annotation, significantly hinders data-driven approaches. Existing time-series generation models, optimized for abundant normal data, struggle to capture fault distributions in few-shot scenarios, producing samples that lack authenticity and diversity due to the large domain gap and high intra-class variability of faults. To address this, we propose a novel few-shot fault time-series generation framework based on diffusion models. Our approach employs a positive-negative difference adapter, leveraging pre-trained normal data distributions to model the discrepancies between normal and fault domains for accurate fault synthesis. Additionally, a diversity loss is introduced to prevent mode collapse, encouraging the generation of diverse fault samples through inter-sample difference regularization. Experimental results demonstrate that our model significantly outperforms traditional methods in authenticity and diversity, achieving state-of-the-art performance on key benchmarks.
MTQA:Matrix of Thought for Enhanced Reasoning in Complex Question Answering
Sep 04, 2025Complex Question Answering (QA) is a fundamental and challenging task in NLP. While large language models (LLMs) exhibit impressive performance in QA, they suffer from significant performance degradation when facing complex and abstract QA tasks due to insufficient reasoning capabilities. Works such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) aim to enhance LLMs' reasoning abilities, but they face issues such as in-layer redundancy in tree structures and single paths in chain structures. Although some studies utilize Retrieval-Augmented Generation (RAG) methods to assist LLMs in reasoning, the challenge of effectively utilizing large amounts of information involving multiple entities and hops remains critical. To address this, we propose the Matrix of Thought (MoT), a novel and efficient LLM thought structure. MoT explores the problem in both horizontal and vertical dimensions through the "column-cell communication" mechanism, enabling LLMs to actively engage in multi-strategy and deep-level thinking, reducing redundancy within the column cells and enhancing reasoning capabilities. Furthermore, we develop a fact-correction mechanism by constructing knowledge units from retrieved knowledge graph triples and raw text to enhance the initial knowledge for LLM reasoning and correct erroneous answers. This leads to the development of an efficient and accurate QA framework (MTQA). Experimental results show that our framework outperforms state-of-the-art methods on four widely-used datasets in terms of F1 and EM scores, with reasoning time only 14.4\% of the baseline methods, demonstrating both its efficiency and accuracy. The code for this framework is available at https://github.com/lyfiter/mtqa.
KGV: Integrating Large Language Models with Knowledge Graphs for Cyber Threat Intelligence Credibility Assessment
Aug 15, 2024Cyber threat intelligence is a critical tool that many organizations and individuals use to protect themselves from sophisticated, organized, persistent, and weaponized cyber attacks. However, few studies have focused on the quality assessment of threat intelligence provided by intelligence platforms, and this work still requires manual analysis by cybersecurity experts. In this paper, we propose a knowledge graph-based verifier, a novel Cyber Threat Intelligence (CTI) quality assessment framework that combines knowledge graphs and Large Language Models (LLMs). Our approach introduces LLMs to automatically extract OSCTI key claims to be verified and utilizes a knowledge graph consisting of paragraphs for fact-checking. This method differs from the traditional way of constructing complex knowledge graphs with entities as nodes. By constructing knowledge graphs with paragraphs as nodes and semantic similarity as edges, it effectively enhances the semantic understanding ability of the model and simplifies labeling requirements. Additionally, to fill the gap in the research field, we created and made public the first dataset for threat intelligence assessment from heterogeneous sources. To the best of our knowledge, this work is the first to create a dataset on threat intelligence reliability verification, providing a reference for future research. Experimental results show that KGV (Knowledge Graph Verifier) significantly improves the performance of LLMs in intelligence quality assessment. Compared with traditional methods, we reduce a large amount of data annotation while the model still exhibits strong reasoning capabilities. Finally, our method can achieve XXX accuracy in network threat assessment.
Federated Hypergraph Learning with Hyperedge Completion
Aug 09, 2024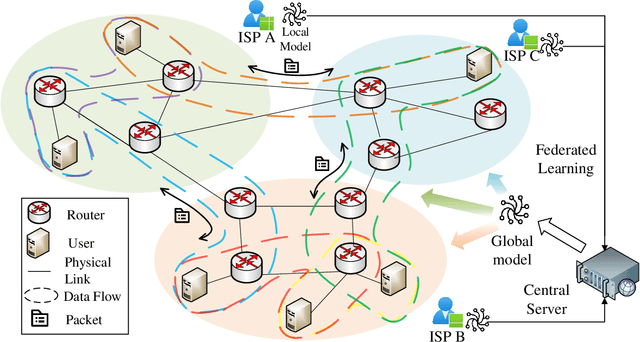
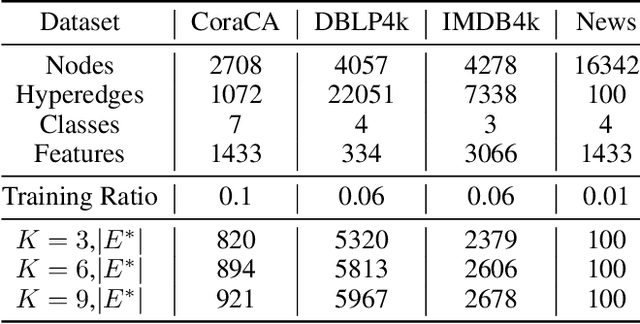
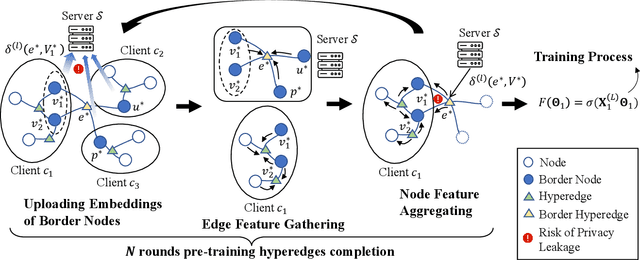
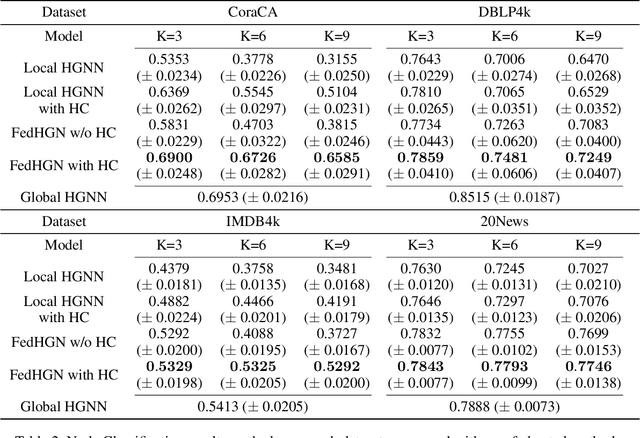
Hypergraph neural networks enhance conventional graph neural networks by capturing high-order relationships among nodes, which proves vital in data-rich environments where interactions are not merely pairwise. As data complexity and interconnectivity grow, it is common for graph-structured data to be split and stored in a distributed manner, underscoring the necessity of federated learning on subgraphs. In this work, we propose FedHGN, a novel algorithm for federated hypergraph learning. Our algorithm utilizes subgraphs of a hypergraph stored on distributed devices to train local HGNN models in a federated manner:by collaboratively developing an effective global HGNN model through sharing model parameters while preserving client privacy. Additionally, considering that hyperedges may span multiple clients, a pre-training step is employed before the training process in which cross-client hyperedge feature gathering is performed at the central server. In this way, the missing cross-client information can be supplemented from the central server during the node feature aggregation phase. Experimental results on seven real-world datasets confirm the effectiveness of our approach and demonstrate its performance advantages over traditional federated graph learning methods.
Large Language Model assisted End-to-End Network Health Management based on Multi-Scale Semanticization
Jun 12, 2024



Network device and system health management is the foundation of modern network operations and maintenance. Traditional health management methods, relying on expert identification or simple rule-based algorithms, struggle to cope with the dynamic heterogeneous networks (DHNs) environment. Moreover, current state-of-the-art distributed anomaly detection methods, which utilize specific machine learning techniques, lack multi-scale adaptivity for heterogeneous device information, resulting in unsatisfactory diagnostic accuracy for DHNs. In this paper, we develop an LLM-assisted end-to-end intelligent network health management framework. The framework first proposes a Multi-Scale Semanticized Anomaly Detection Model (MSADM), incorporating semantic rule trees with an attention mechanism to address the multi-scale anomaly detection problem in DHNs. Secondly, a chain-of-thought-based large language model is embedded in downstream to adaptively analyze the fault detection results and produce an analysis report with detailed fault information and optimization strategies. Experimental results show that the accuracy of our proposed MSADM for heterogeneous network entity anomaly detection is as high as 91.31\%.
UniSA: Unified Generative Framework for Sentiment Analysis
Sep 04, 2023



Sentiment analysis is a crucial task that aims to understand people's emotional states and predict emotional categories based on multimodal information. It consists of several subtasks, such as emotion recognition in conversation (ERC), aspect-based sentiment analysis (ABSA), and multimodal sentiment analysis (MSA). However, unifying all subtasks in sentiment analysis presents numerous challenges, including modality alignment, unified input/output forms, and dataset bias. To address these challenges, we propose a Task-Specific Prompt method to jointly model subtasks and introduce a multimodal generative framework called UniSA. Additionally, we organize the benchmark datasets of main subtasks into a new Sentiment Analysis Evaluation benchmark, SAEval. We design novel pre-training tasks and training methods to enable the model to learn generic sentiment knowledge among subtasks to improve the model's multimodal sentiment perception ability. Our experimental results show that UniSA performs comparably to the state-of-the-art on all subtasks and generalizes well to various subtasks in sentiment analysis.
Differentiated Federated Reinforcement Learning for Dynamic and Heterogeneous Network
Dec 05, 2022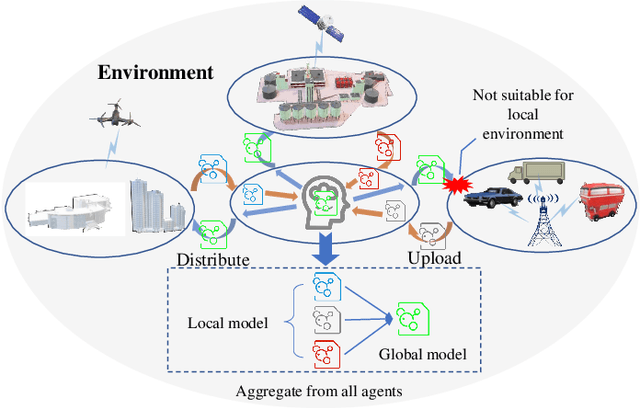
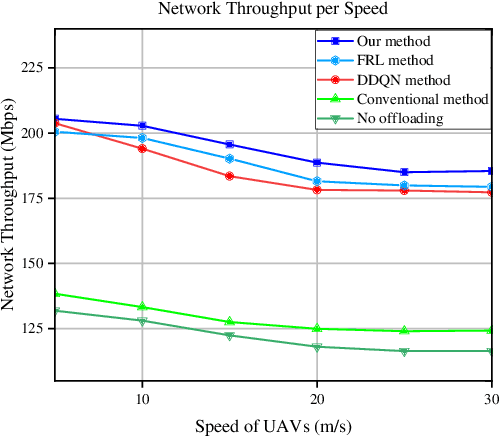
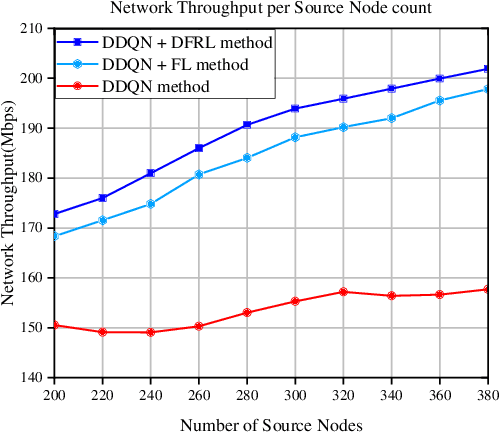
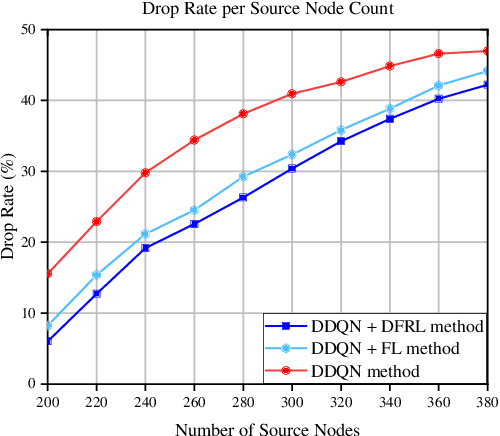
The modern dynamic and heterogeneous network brings differential environments with respective state transition probability to agents, which leads to the local strategy trap problem of traditional federated reinforcement learning (FRL) based network optimization algorithm. To solve this problem, we propose a novel Differentiated Federated Reinforcement Learning (DFRL), which evolves the global policy model integration and local inference with the global policy model in traditional FRL to a collaborative learning process with parallel global trends learning and differential local policy model learning. In the DFRL, the local policy learning model is adaptively updated with the global trends model and local environment and achieves better differentiated adaptation. We evaluate the outperformance of the proposal compared with the state-of-the-art FRL in a classical CartPole game with heterogeneous environments. Furthermore, we implement the proposal in the heterogeneous Space-air-ground Integrated Network (SAGIN) for the classical traffic offloading problem in network. The simulation result shows that the proposal shows better global performance and fairness than baselines in terms of throughput, delay, and packet drop rate.
EmoCaps: Emotion Capsule based Model for Conversational Emotion Recognition
Mar 25, 2022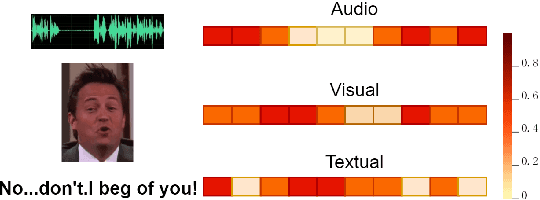


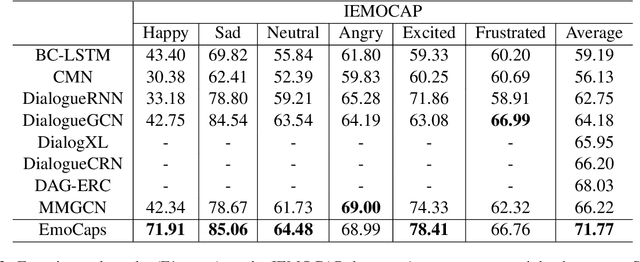
Emotion recognition in conversation (ERC) aims to analyze the speaker's state and identify their emotion in the conversation. Recent works in ERC focus on context modeling but ignore the representation of contextual emotional tendency. In order to extract multi-modal information and the emotional tendency of the utterance effectively, we propose a new structure named Emoformer to extract multi-modal emotion vectors from different modalities and fuse them with sentence vector to be an emotion capsule. Furthermore, we design an end-to-end ERC model called EmoCaps, which extracts emotion vectors through the Emoformer structure and obtain the emotion classification results from a context analysis model. Through the experiments with two benchmark datasets, our model shows better performance than the existing state-of-the-art models.
SEOVER: Sentence-level Emotion Orientation Vector based Conversation Emotion Recognition Model
Jun 16, 2021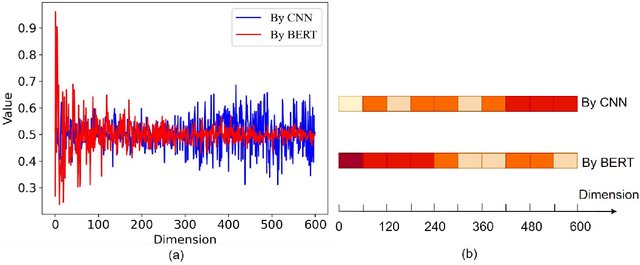
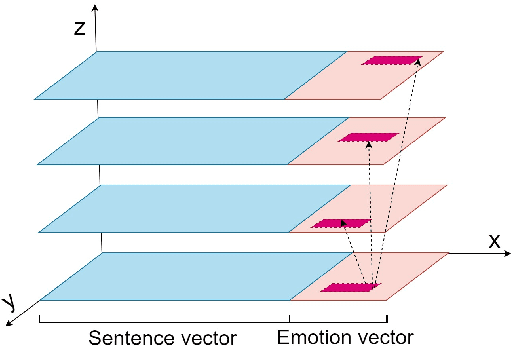
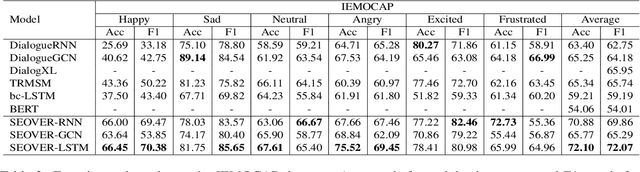
For the task of conversation emotion recognition, recent works focus on speaker relationship modeling but ignore the role of utterance's emotional tendency.In this paper, we propose a new expression paradigm of sentence-level emotion orientation vector to model the potential correlation of emotions between sentence vectors. Based on it, we design an emotion recognition model, which extracts the sentence-level emotion orientation vectors from the language model and jointly learns from the dialogue sentiment analysis model and extracted sentence-level emotion orientation vectors to identify the speaker's emotional orientation during the conversation. We conduct experiments on two benchmark datasets and compare them with the five baseline models.The experimental results show that our model has better performance on all data sets.