 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoCaps: Emotion Capsule based Model for Conversational Emotion Recognition
Paper and Code
Mar 25, 2022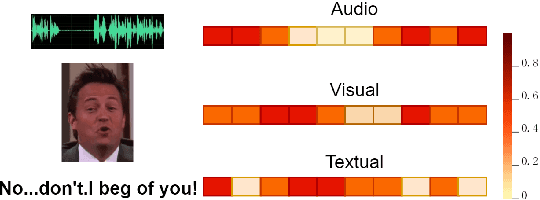


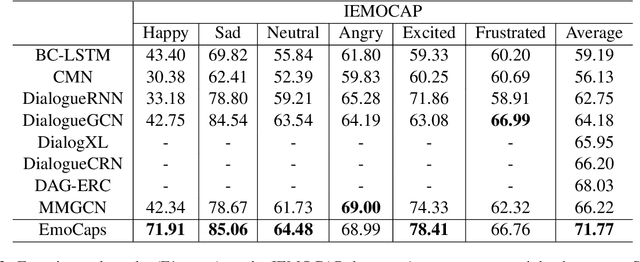
Emotion recognition in conversation (ERC) aims to analyze the speaker's state and identify their emotion in the conversation. Recent works in ERC focus on context modeling but ignore the representation of contextual emotional tendency. In order to extract multi-modal information and the emotional tendency of the utterance effectively, we propose a new structure named Emoformer to extract multi-modal emotion vectors from different modalities and fuse them with sentence vector to be an emotion capsule. Furthermore, we design an end-to-end ERC model called EmoCaps, which extracts emotion vectors through the Emoformer structure and obtain the emotion classification results from a context analysis model. Through the experiments with two benchmark datasets, our model shows better performance than the existing state-of-the-art models.