 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAP-CAP: Advancing High-Quality Data Synthesis for Animal Pose Estimation via a Controllable Image Generation Pipeline
Apr 01, 2025The task of 2D animal pose estimation plays a crucial role in advancing deep learning applications in animal behavior analysis and ecological research. Despite notable progress in some existing approaches, our study reveals that the scarcity of high-quality datasets remains a significant bottleneck, limiting the full potential of current methods. To address this challenge, we propose a novel Controllable Image Generation Pipeline for synthesizing animal pose estimation data, termed AP-CAP. Within this pipeline, we introduce a Multi-Modal Animal Image Generation Model capable of producing images with expected poses. To enhance the quality and diversity of the generated data, we further propose three innovative strategies: (1) Modality-Fusion-Based Animal Image Synthesis Strategy to integrate multi-source appearance representations, (2) Pose-Adjustment-Based Animal Image Synthesis Strategy to dynamically capture diverse pose variations, and (3) Caption-Enhancement-Based Animal Image Synthesis Strategy to enrich visual semantic understanding. Leveraging the proposed model and strategies, we create the MPCH Dataset (Modality-Pose-Caption Hybrid), the first hybrid dataset that innovatively combines synthetic and real data, establishing the largest-scale multi-source heterogeneous benchmark repository for animal pose estimation to date. Extensive experiments demonstrate the superiority of our method in improving both the performance and generalization capability of animal pose estimators.
A Simple yet Effective Subway Self-positioning Method based on Aerial-view Sleeper Detection
Oct 12, 2024



With the rapid development of urban underground rail vehicles,subway positioning, which plays a fundamental role in the traffic navigation and collision avoidance systems, has become a research hot-spot these years. Most current subway positioning methods rely on localization beacons densely pre-installed alongside the railway tracks, requiring massive costs for infrastructure and maintenance, while commonly lacking flexibility and anti-interference ability. In this paper, we propose a low-cost and real-time visual-assisted self-localization framework to address the robust and convenient positioning problem for subways. Firstly, we perform aerial view rail sleeper detection based on the fast and efficient YOLOv8n network. The detection results are then used to achieve real-time correction of mileage values combined with geometric positioning information, obtaining precise subway locations. Front camera Videos for subway driving scenes along a 6.9 km route are collected and annotated from the simulator for validation of the proposed method. Experimental results show that our aerial view sleeper detection algorithm can efficiently detect sleeper positions with F1-score of 0.929 at 1111 fps, and that the proposed positioning framework achieves a mean percentage error of 0.1\%, demonstrating its continuous and high-precision self-localization capability.
Fast and Accurate Online Video Object Segmentation via Tracking Parts
Jun 06, 2018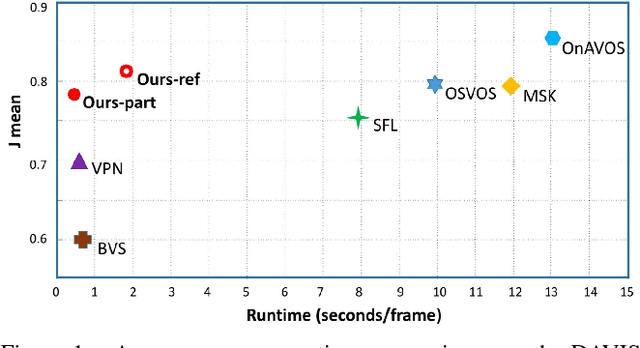
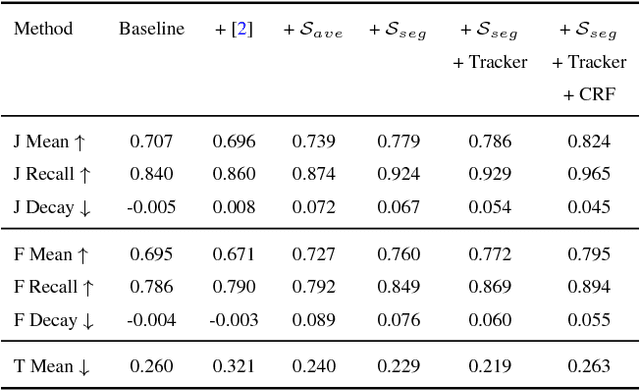
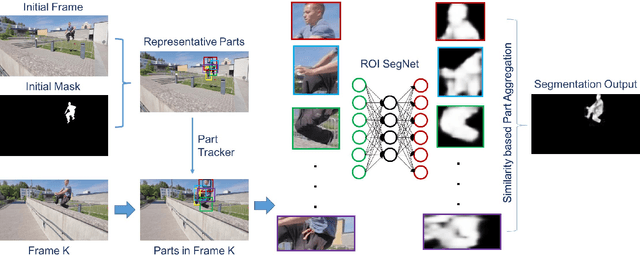
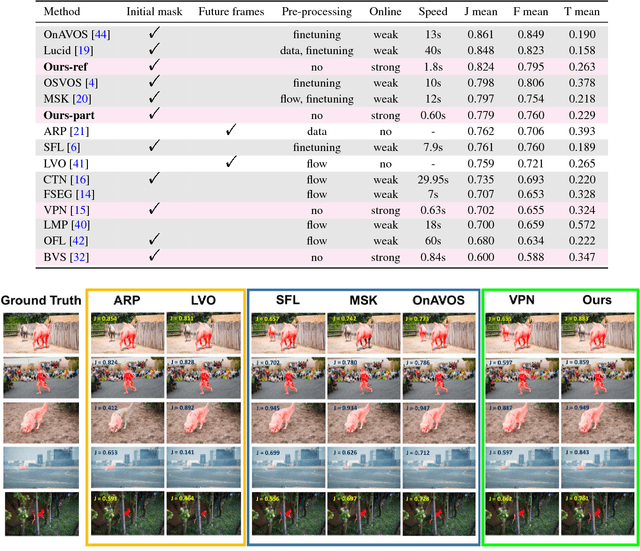
Online video object segmentation is a challenging task as it entails to process the image sequence timely and accurately. To segment a target object through the video, numerous CNN-based methods have been developed by heavily finetuning on the object mask in the first frame, which is time-consuming for online applications. In this paper, we propose a fast and accurate video object segmentation algorithm that can immediately start the segmentation process once receiving the images. We first utilize a part-based tracking method to deal with challenging factors such as large deformation, occlusion, and cluttered background. Based on the tracked bounding boxes of parts, we construct a region-of-interest segmentation network to generate part masks. Finally, a similarity-based scoring function is adopted to refine these object parts by comparing them to the visual information in the first frame. Our method performs favorably against state-of-the-art algorithms in accuracy on the DAVIS benchmark dataset, while achieving much faster runtime performance.
SegFlow: Joint Learning for Video Object Segmentation and Optical Flow
Sep 20, 2017
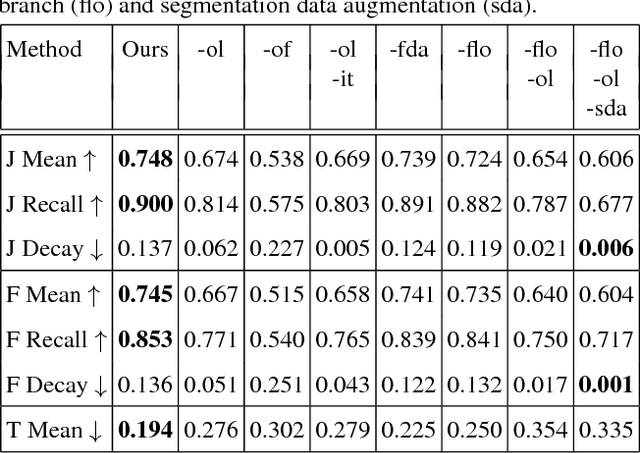
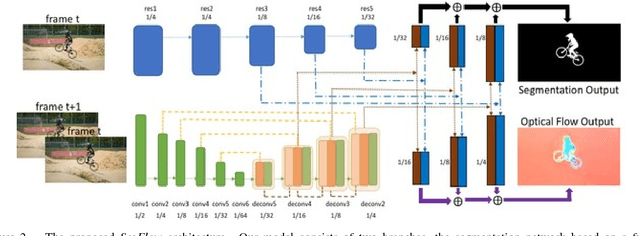

This paper proposes an end-to-end trainable network, SegFlow, for simultaneously predicting pixel-wise object segmentation and optical flow in videos. The proposed SegFlow has two branches where useful information of object segmentation and optical flow is propagated bidirectionally in a unified framework. The segmentation branch is based on a fully convolutional network, which has been proved effective in image segmentation task, and the optical flow branch takes advantage of the FlowNet model. The unified framework is trained iteratively offline to learn a generic notion, and fine-tuned online for specific objects. Extensive experiments on both the video object segmentation and optical flow datasets demonstrate that introducing optical flow improves the performance of segmentation and vice versa, against the state-of-the-art algorithms.
Learning to Segment Instances in Videos with Spatial Propagation Network
Sep 14, 2017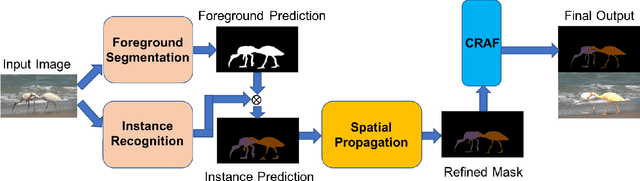
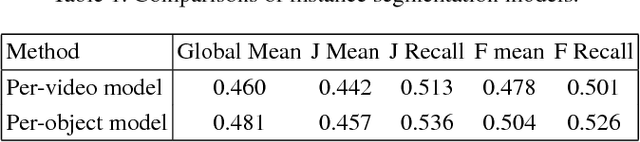
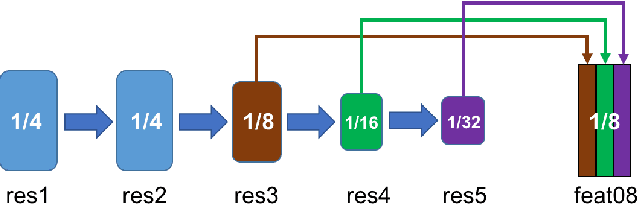
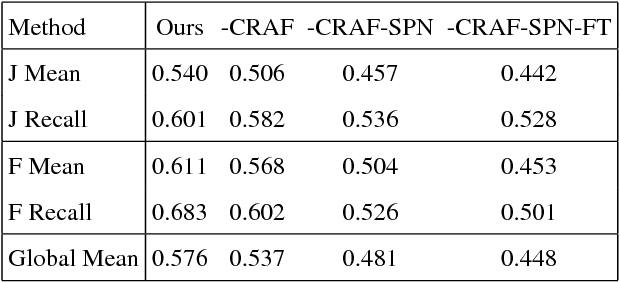
We propose a deep learning-based framework for instance-level object segmentation. Our method mainly consists of three steps. First, We train a generic model based on ResNet-101 for foreground/background segmentations. Second, based on this generic model, we fine-tune it to learn instance-level models and segment individual objects by using augmented object annotations in first frames of test videos. To distinguish different instances in the same video, we compute a pixel-level score map for each object from these instance-level models. Each score map indicates the objectness likelihood and is only computed within the foreground mask obtained in the first step. To further refine this per frame score map, we learn a spatial propagation network. This network aims to learn how to propagate a coarse segmentation mask spatially based on the pairwise similarities in each frame. In addition, we apply a filter on the refined score map that aims to recognize the best connected region using spatial and temporal consistencies in the video. Finally, we decide the instance-level object segmentation in each video by comparing score maps of different instances.