 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSideRT: A Real-time Pure Transformer Architecture for Single Image Depth Estimation
Apr 29, 2022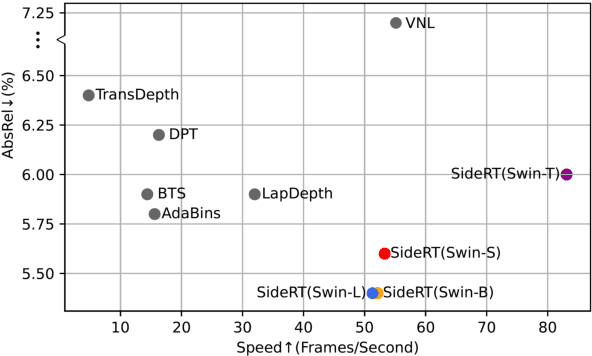
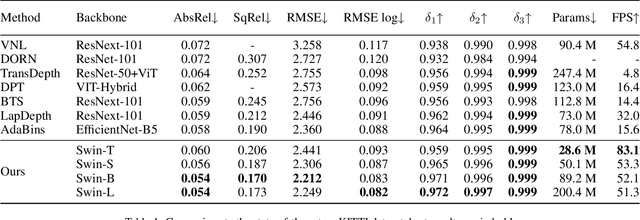
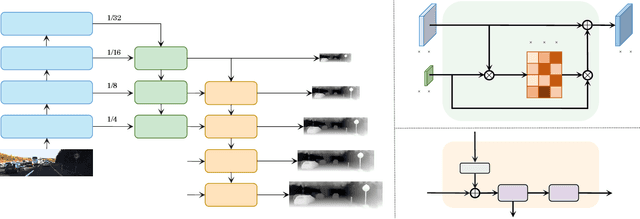
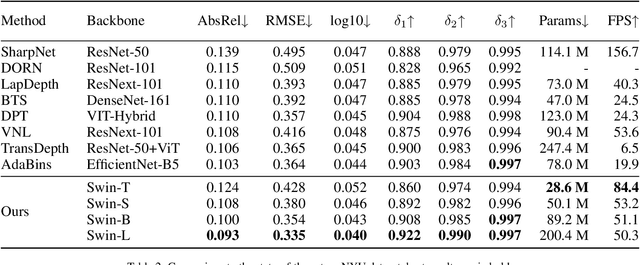
Since context modeling is critical for estimating depth from a single image, researchers put tremendous effort into obtaining global context. Many global manipulations are designed for traditional CNN-based architectures to overcome the locality of convolutions. Attention mechanisms or transformers originally designed for capturing long-range dependencies might be a better choice, but usually complicates architectures and could lead to a decrease in inference speed. In this work, we propose a pure transformer architecture called SideRT that can attain excellent predictions in real-time. In order to capture better global context, Cross-Scale Attention (CSA) and Multi-Scale Refinement (MSR) modules are designed to work collaboratively to fuse features of different scales efficiently. CSA modules focus on fusing features of high semantic similarities, while MSR modules aim to fuse features at corresponding positions. These two modules contain a few learnable parameters without convolutions, based on which a lightweight yet effective model is built. This architecture achieves state-of-the-art performances in real-time (51.3 FPS) and becomes much faster with a reasonable performance drop on a smaller backbone Swin-T (83.1 FPS). Furthermore, its performance surpasses the previous state-of-the-art by a large margin, improving AbsRel metric 6.9% on KITTI and 9.7% on NYU. To the best of our knowledge, this is the first work to show that transformer-based networks can attain state-of-the-art performance in real-time in the single image depth estimation field. Code will be made available soon.