 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHy-Embodied-0.5-VLA: From Vision-Language-Action Models to a Real-World Robot Learning Stack
Jun 12, 2026In this report, we present Hy-Embodied-0.5-VLA, abbreviated as HyVLA-0.5, an end-to-end system that spans the full robot learning stack: data collection, model design, continued pre-training and supervised fine-tuning, RL post-training, and real-world deployment. Each component serves a distinct role in this stack.
HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
Apr 08, 2026We introduce HY-Embodied-0.5, a family of foundation models specifically designed for real-world embodied agents. To bridge the gap between general Vision-Language Models (VLMs) and the demands of embodied agents, our models are developed to enhance the core capabilities required by embodied intelligence: spatial and temporal visual perception, alongside advanced embodied reasoning for prediction, interaction, and planning. The HY-Embodied-0.5 suite comprises two primary variants: an efficient model with 2B activated parameters designed for edge deployment, and a powerful model with 32B activated parameters targeted for complex reasoning. To support the fine-grained visual perception essential for embodied tasks, we adopt a Mixture-of-Transformers (MoT) architecture to enable modality-specific computing. By incorporating latent tokens, this design effectively enhances the perceptual representation of the models. To improve reasoning capabilities, we introduce an iterative, self-evolving post-training paradigm. Furthermore, we employ on-policy distillation to transfer the advanced capabilities of the large model to the smaller variant, thereby maximizing the performance potential of the compact model. Extensive evaluations across 22 benchmarks, spanning visual perception, spatial reasoning, and embodied understanding, demonstrate the effectiveness of our approach. Our MoT-2B model outperforms similarly sized state-of-the-art models on 16 benchmarks, while the 32B variant achieves performance comparable to frontier models such as Gemini 3.0 Pro. In downstream robot control experiments, we leverage our robust VLM foundation to train an effective Vision-Language-Action (VLA) model, achieving compelling results in real-world physical evaluations. Code and models are open-sourced at https://github.com/Tencent-Hunyuan/HY-Embodied.
Multi-Scale Deformable Transformers for Student Learning Behavior Detection in Smart Classroom
Oct 10, 2024The integration of Artificial Intelligence into the modern educational system is rapidly evolving, particularly in monitoring student behavior in classrooms, a task traditionally dependent on manual observation. This conventional method is notably inefficient, prompting a shift toward more advanced solutions like computer vision. However, existing target detection models face significant challenges such as occlusion, blurring, and scale disparity, which are exacerbated by the dynamic and complex nature of classroom settings. Furthermore, these models must adeptly handle multiple target detection. To overcome these obstacles, we introduce the Student Learning Behavior Detection with Multi-Scale Deformable Transformers (SCB-DETR), an innovative approach that utilizes large convolutional kernels for upstream feature extraction, and multi-scale feature fusion. This technique significantly improves the detection capabilities for multi-scale and occluded targets, offering a robust solution for analyzing student behavior. SCB-DETR establishes an end-to-end framework that simplifies the detection process and consistently outperforms other deep learning methods. Employing our custom Student Classroom Behavior (SCBehavior) Dataset, SCB-DETR achieves a mean Average Precision (mAP) of 0.626, which is a 1.5% improvement over the baseline model's mAP and a 6% increase in AP50. These results demonstrate SCB-DETR's superior performance in handling the uneven distribution of student behaviors and ensuring precise detection in dynamic classroom environments.
SideRT: A Real-time Pure Transformer Architecture for Single Image Depth Estimation
Apr 29, 2022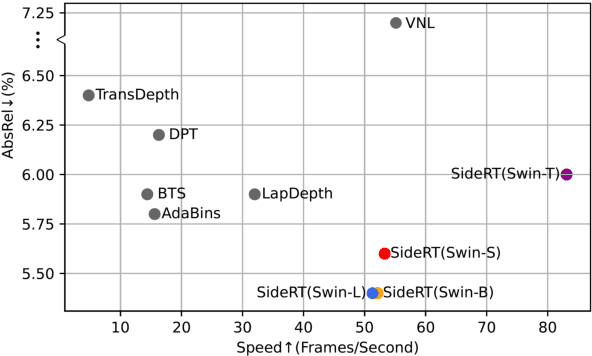
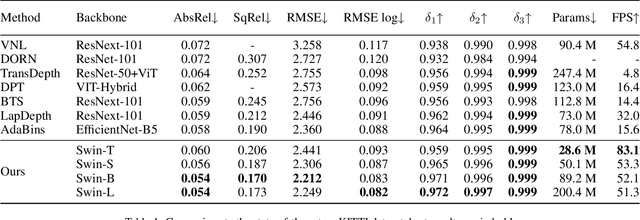
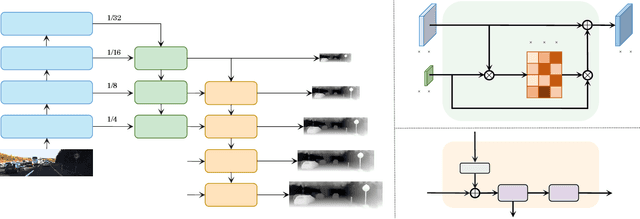
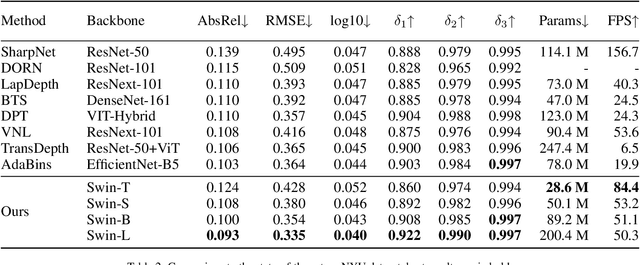
Since context modeling is critical for estimating depth from a single image, researchers put tremendous effort into obtaining global context. Many global manipulations are designed for traditional CNN-based architectures to overcome the locality of convolutions. Attention mechanisms or transformers originally designed for capturing long-range dependencies might be a better choice, but usually complicates architectures and could lead to a decrease in inference speed. In this work, we propose a pure transformer architecture called SideRT that can attain excellent predictions in real-time. In order to capture better global context, Cross-Scale Attention (CSA) and Multi-Scale Refinement (MSR) modules are designed to work collaboratively to fuse features of different scales efficiently. CSA modules focus on fusing features of high semantic similarities, while MSR modules aim to fuse features at corresponding positions. These two modules contain a few learnable parameters without convolutions, based on which a lightweight yet effective model is built. This architecture achieves state-of-the-art performances in real-time (51.3 FPS) and becomes much faster with a reasonable performance drop on a smaller backbone Swin-T (83.1 FPS). Furthermore, its performance surpasses the previous state-of-the-art by a large margin, improving AbsRel metric 6.9% on KITTI and 9.7% on NYU. To the best of our knowledge, this is the first work to show that transformer-based networks can attain state-of-the-art performance in real-time in the single image depth estimation field. Code will be made available soon.