 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionNet: A Drivable-space-based Interactive Motion Prediction Network for Autonomous Driving
Paper and Code
Jan 08, 2020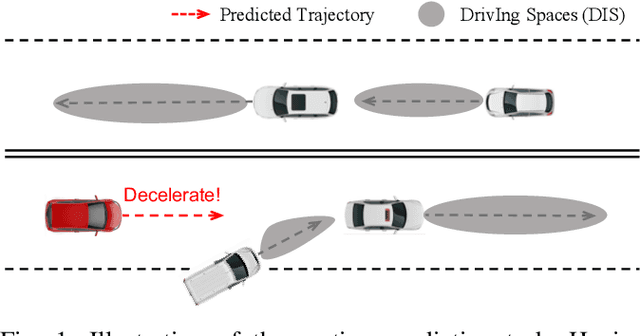
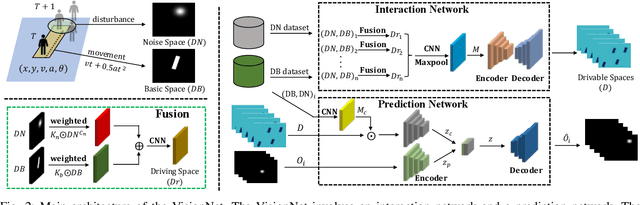
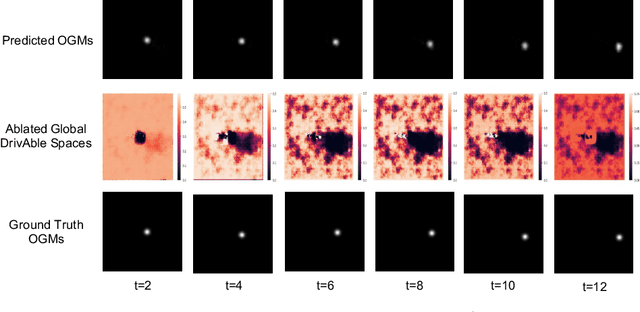
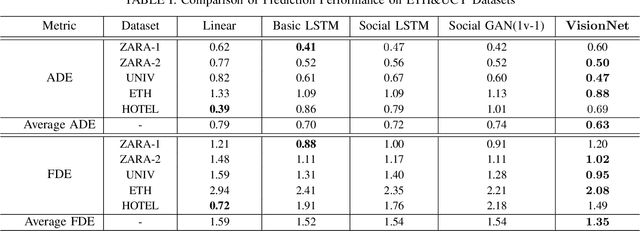
The comprehension of environmental traffic situation largely ensures the driving safety of autonomous vehicles. Recently, the mission has been investigated by plenty of researches, while it is hard to be well addressed due to the limitation of collective influence in complex scenarios. These approaches model the interactions through the spatial relations between the target obstacle and its neighbors. However, they oversimplify the challenge since the training stage of the interactions lacks effective supervision. As a result, these models are far from promising. More intuitively, we transform the problem into calculating the interaction-aware drivable spaces and propose the CNN-based VisionNet for trajectory prediction. The VisionNet accepts a sequence of motion states, i.e., location, velocity, and acceleration, to estimate the future drivable spaces. The reified interactions significantly increase the interpretation ability of the VisionNet and refine the prediction. To further advance the performance, we propose an interactive loss to guide the generation of the drivable spaces. Experiments on multiple public datasets demonstrate the effectiveness of the proposed VisionNet.