 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Morphological Embeddings for the Russian Language
Mar 11, 2021
A number of morphology-based word embedding models were introduced in recent years. However, their evaluation was mostly limited to English, which is known to be a morphologically simple language. In this paper, we explore whether and to what extent incorporating morphology into word embeddings improves performance on downstream NLP tasks, in the case of morphologically rich Russian language. NLP tasks of our choice are POS tagging, Chunking, and NER -- for Russian language, all can be mostly solved using only morphology without understanding the semantics of words. Our experiments show that morphology-based embeddings trained with Skipgram objective do not outperform existing embedding model -- FastText. Moreover, a more complex, but morphology unaware model, BERT, allows to achieve significantly greater performance on the tasks that presumably require understanding of a word's morphology.
Evaluation of Morphological Embeddings for English and Russian Languages
Mar 11, 2021



This paper evaluates morphology-based embeddings for English and Russian languages. Despite the interest and introduction of several morphology-based word embedding models in the past and acclaimed performance improvements on word similarity and language modeling tasks, in our experiments, we did not observe any stable preference over two of our baseline models - SkipGram and FastText. The performance exhibited by morphological embeddings is the average of the two baselines mentioned above.
Hierarchical Transformer for Multilingual Machine Translation
Mar 05, 2021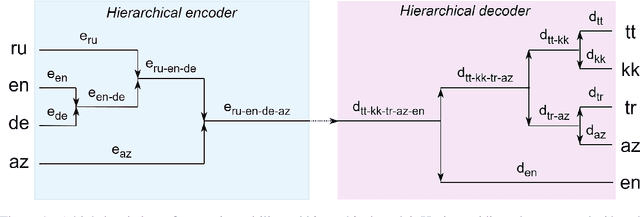

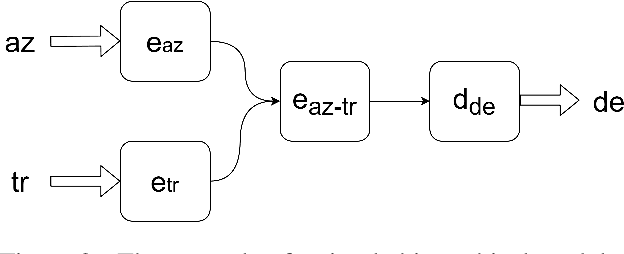
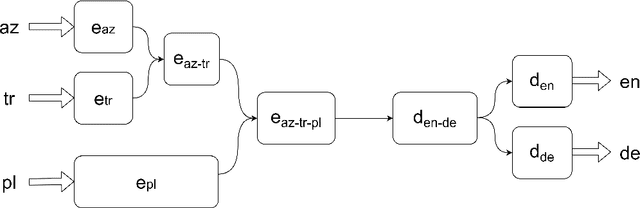
The choice of parameter sharing strategy in multilingual machine translation models determines how optimally parameter space is used and hence, directly influences ultimate translation quality. Inspired by linguistic trees that show the degree of relatedness between different languages, the new general approach to parameter sharing in multilingual machine translation was suggested recently. The main idea is to use these expert language hierarchies as a basis for multilingual architecture: the closer two languages are, the more parameters they share. In this work, we test this idea using the Transformer architecture and show that despite the success in previous work there are problems inherent to training such hierarchical models. We demonstrate that in case of carefully chosen training strategy the hierarchical architecture can outperform bilingual models and multilingual models with full parameter sharing.