 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Foundation Models for Mixed Integer Linear Programming
Oct 10, 2024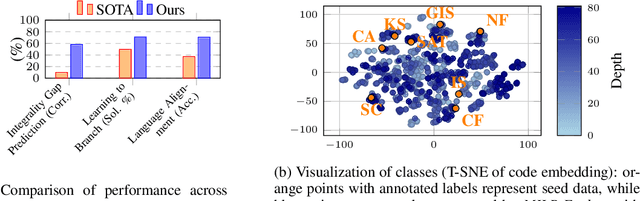

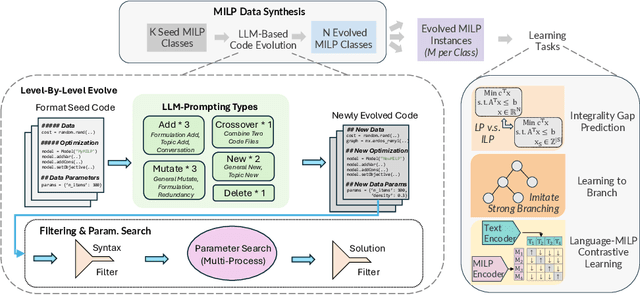
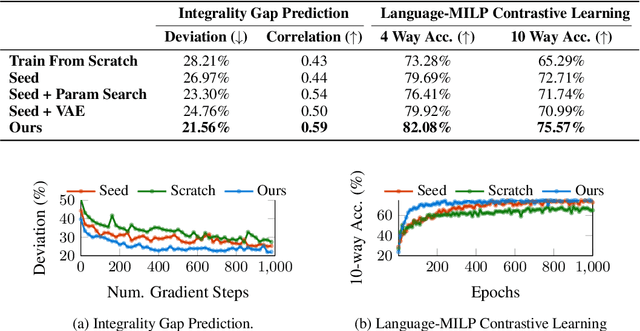
Mixed Integer Linear Programming (MILP) is essential for modeling complex decision-making problems but faces challenges in computational tractability and requires expert formulation. Current deep learning approaches for MILP focus on specific problem classes and do not generalize to unseen classes. To address this shortcoming, we take a foundation model training approach, where we train a single deep learning model on a diverse set of MILP problems to generalize across problem classes. As existing datasets for MILP lack diversity and volume, we introduce MILP-Evolve, a novel LLM-based evolutionary framework that is capable of generating a large set of diverse MILP classes with an unlimited amount of instances. We study our methodology on three key learning tasks that capture diverse aspects of MILP: (1) integrality gap prediction, (2) learning to branch, and (3) a new task of aligning MILP instances with natural language descriptions. Our empirical results show that models trained on the data generated by MILP-Evolve achieve significant improvements on unseen problems, including MIPLIB benchmarks. Our work highlights the potential of moving towards a foundation model approach for MILP that can generalize to a broad range of MILP applications. We are committed to fully open-sourcing our work to advance further research.
Small Language Models for Application Interactions: A Case Study
May 23, 2024



We study the efficacy of Small Language Models (SLMs) in facilitating application usage through natural language interactions. Our focus here is on a particular internal application used in Microsoft for cloud supply chain fulfilment. Our experiments show that small models can outperform much larger ones in terms of both accuracy and running time, even when fine-tuned on small datasets. Alongside these results, we also highlight SLM-based system design considerations.
Large Language Models for Supply Chain Optimization
Jul 13, 2023



Supply chain operations traditionally involve a variety of complex decision making problems. Over the last few decades, supply chains greatly benefited from advances in computation, which allowed the transition from manual processing to automation and cost-effective optimization. Nonetheless, business operators still need to spend substantial efforts in explaining and interpreting the optimization outcomes to stakeholders. Motivated by the recent advances in Large Language Models (LLMs), we study how this disruptive technology can help bridge the gap between supply chain automation and human comprehension and trust thereof. We design OptiGuide -- a framework that accepts as input queries in plain text, and outputs insights about the underlying optimization outcomes. Our framework does not forgo the state-of-the-art combinatorial optimization technology, but rather leverages it to quantitatively answer what-if scenarios (e.g., how would the cost change if we used supplier B instead of supplier A for a given demand?). Importantly, our design does not require sending proprietary data over to LLMs, which can be a privacy concern in some circumstances. We demonstrate the effectiveness of our framework on a real server placement scenario within Microsoft's cloud supply chain. Along the way, we develop a general evaluation benchmark, which can be used to evaluate the accuracy of the LLM output in other scenarios.
A Deep Learning Perspective on Network Routing
Mar 05, 2023Routing is, arguably, the most fundamental task in computer networking, and the most extensively studied one. A key challenge for routing in real-world environments is the need to contend with uncertainty about future traffic demands. We present a new approach to routing under demand uncertainty: tackling this challenge as stochastic optimization, and employing deep learning to learn complex patterns in traffic demands. We show that our method provably converges to the global optimum in well-studied theoretical models of multicommodity flow. We exemplify the practical usefulness of our approach by zooming in on the real-world challenge of traffic engineering (TE) on wide-area networks (WANs). Our extensive empirical evaluation on real-world traffic and network topologies establishes that our approach's TE quality almost matches that of an (infeasible) omniscient oracle, outperforming previously proposed approaches, and also substantially lowers runtimes.