 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscretion in the Loop: Human Expertise in Algorithm-Assisted College Advising
May 19, 2025In higher education, many institutions use algorithmic alerts to flag at-risk students and deliver advising at scale. While much research has focused on evaluating algorithmic predictions, relatively little is known about how discretionary interventions by human experts shape outcomes in algorithm-assisted settings. We study this question using rich quantitative and qualitative data from a randomized controlled trial of an algorithm-assisted advising program at Georgia State University. Taking a mixed-methods approach, we examine whether and how advisors use context unavailable to an algorithm to guide interventions and influence student success. We develop a causal graphical framework for human expertise in the interventional setting, extending prior work on discretion in purely predictive settings. We then test a necessary condition for discretionary expertise using structured advisor logs and student outcomes data, identifying several interventions that meet the criterion for statistical significance. Accordingly, we estimate that 2 out of 3 interventions taken by advisors in the treatment arm were plausibly "expertly targeted" to students using non-algorithmic context. Systematic qualitative analysis of advisor notes corroborates these findings, showing that advisors incorporate diverse forms of contextual information--such as personal circumstances, financial issues, and student engagement--into their decisions. Finally, we explore the broader implications of human discretion for long-term outcomes and equity, using heterogeneous treatment effect estimation. Our results offer theoretical and practical insight into the real-world effectiveness of algorithm-supported college advising, and underscore the importance of accounting for human expertise in the design, evaluation, and implementation of algorithmic decision systems.
Measuring Strategization in Recommendation: Users Adapt Their Behavior to Shape Future Content
May 09, 2024



Most modern recommendation algorithms are data-driven: they generate personalized recommendations by observing users' past behaviors. A common assumption in recommendation is that how a user interacts with a piece of content (e.g., whether they choose to "like" it) is a reflection of the content, but not of the algorithm that generated it. Although this assumption is convenient, it fails to capture user strategization: that users may attempt to shape their future recommendations by adapting their behavior to the recommendation algorithm. In this work, we test for user strategization by conducting a lab experiment and survey. To capture strategization, we adopt a model in which strategic users select their engagement behavior based not only on the content, but also on how their behavior affects downstream recommendations. Using a custom music player that we built, we study how users respond to different information about their recommendation algorithm as well as to different incentives about how their actions affect downstream outcomes. We find strong evidence of strategization across outcome metrics, including participants' dwell time and use of "likes." For example, participants who are told that the algorithm mainly pays attention to "likes" and "dislikes" use those functions 1.9x more than participants told that the algorithm mainly pays attention to dwell time. A close analysis of participant behavior (e.g., in response to our incentive conditions) rules out experimenter demand as the main driver of these trends. Further, in our post-experiment survey, nearly half of participants self-report strategizing "in the wild," with some stating that they ignore content they actually like to avoid over-recommendation of that content in the future. Together, our findings suggest that user strategization is common and that platforms cannot ignore the effect of their algorithms on user behavior.
Matching of Users and Creators in Two-Sided Markets with Departures
Jan 17, 2024Many online platforms of today, including social media sites, are two-sided markets bridging content creators and users. Most of the existing literature on platform recommendation algorithms largely focuses on user preferences and decisions, and does not simultaneously address creator incentives. We propose a model of content recommendation that explicitly focuses on the dynamics of user-content matching, with the novel property that both users and creators may leave the platform permanently if they do not experience sufficient engagement. In our model, each player decides to participate at each time step based on utilities derived from the current match: users based on alignment of the recommended content with their preferences, and creators based on their audience size. We show that a user-centric greedy algorithm that does not consider creator departures can result in arbitrarily poor total engagement, relative to an algorithm that maximizes total engagement while accounting for two-sided departures. Moreover, in stark contrast to the case where only users or only creators leave the platform, we prove that with two-sided departures, approximating maximum total engagement within any constant factor is NP-hard. We present two practical algorithms, one with performance guarantees under mild assumptions on user preferences, and another that tends to outperform algorithms that ignore two-sided departures in practice.
Exploration vs. Exploitation in Team Formation
Oct 12, 2018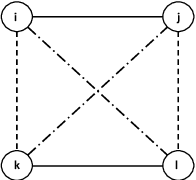
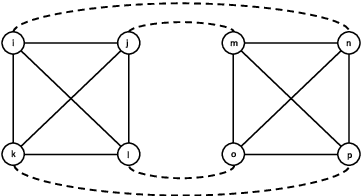
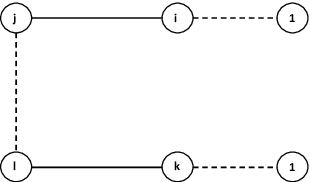
An online labor platform faces an online learning problem in matching workers with jobs and using the performance on these jobs to create better future matches. This learning problem is complicated by the rise of complex tasks on these platforms, such as web development and product design, that require a team of workers to complete. The success of a job is now a function of the skills and contributions of all workers involved, which may be unknown to both the platform and the client who posted the job. These team matchings result in a structured correlation between what is known about the individuals and this information can be utilized to create better future matches. We analyze two natural settings where the performance of a team is dictated by its strongest and its weakest member, respectively. We find that both problems pose an exploration-exploitation tradeoff between learning the performance of untested teams and repeating previously tested teams that resulted in a good performance. We establish fundamental regret bounds and design near-optimal algorithms that uncover several insights into these tradeoffs.