 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration vs. Exploitation in Team Formation
Paper and Code
Oct 12, 2018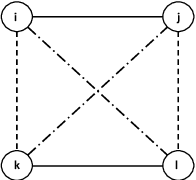
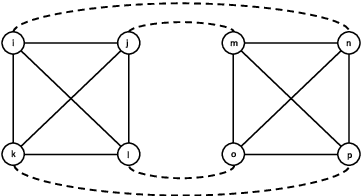
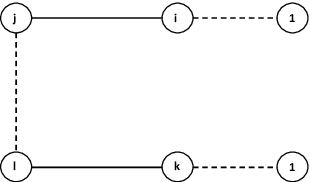
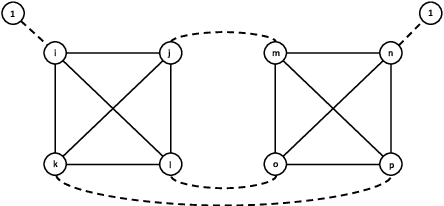
An online labor platform faces an online learning problem in matching workers with jobs and using the performance on these jobs to create better future matches. This learning problem is complicated by the rise of complex tasks on these platforms, such as web development and product design, that require a team of workers to complete. The success of a job is now a function of the skills and contributions of all workers involved, which may be unknown to both the platform and the client who posted the job. These team matchings result in a structured correlation between what is known about the individuals and this information can be utilized to create better future matches. We analyze two natural settings where the performance of a team is dictated by its strongest and its weakest member, respectively. We find that both problems pose an exploration-exploitation tradeoff between learning the performance of untested teams and repeating previously tested teams that resulted in a good performance. We establish fundamental regret bounds and design near-optimal algorithms that uncover several insights into these tradeoffs.