 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrast Sets for Evaluating Language-Guided Robot Policies
Paper and Code
Jun 19, 2024
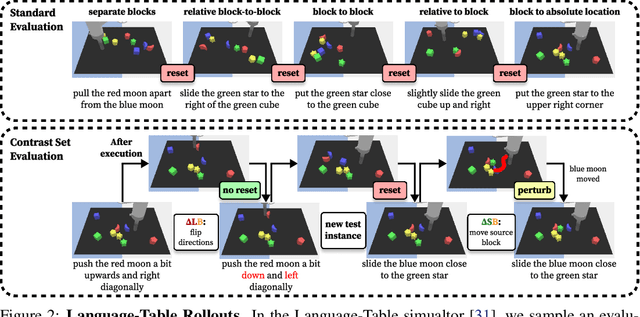
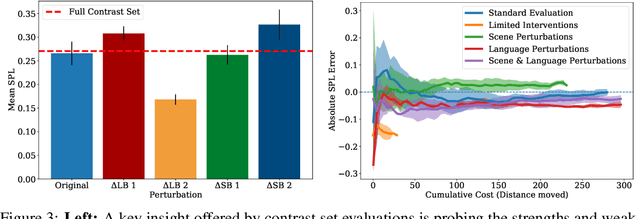

Robot evaluations in language-guided, real world settings are time-consuming and often sample only a small space of potential instructions across complex scenes. In this work, we introduce contrast sets for robotics as an approach to make small, but specific, perturbations to otherwise independent, identically distributed (i.i.d.) test instances. We investigate the relationship between experimenter effort to carry out an evaluation and the resulting estimated test performance as well as the insights that can be drawn from performance on perturbed instances. We use contrast sets to characterize policies at reduced experimenter effort in both a simulated manipulation task and a physical robot vision-and-language navigation task. We encourage the use of contrast set evaluations as a more informative alternative to small scale, i.i.d. demonstrations on physical robots, and as a scalable alternative to industry-scale real world evaluations.