 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobometer: Scaling General-Purpose Robotic Reward Models via Trajectory Comparisons
Mar 02, 2026General-purpose robot reward models are typically trained to predict absolute task progress from expert demonstrations, providing only local, frame-level supervision. While effective for expert demonstrations, this paradigm scales poorly to large-scale robotics datasets where failed and suboptimal trajectories are abundant and assigning dense progress labels is ambiguous. We introduce Robometer, a scalable reward modeling framework that combines intra-trajectory progress supervision with inter-trajectory preference supervision. Robometer is trained with a dual objective: a frame-level progress loss that anchors reward magnitude on expert data, and a trajectory-comparison preference loss that imposes global ordering constraints across trajectories of the same task, enabling effective learning from both real and augmented failed trajectories. To support this formulation at scale, we curate RBM-1M, a reward-learning dataset comprising over one million trajectories spanning diverse robot embodiments and tasks, including substantial suboptimal and failure data. Across benchmarks and real-world evaluations, Robometer learns more generalizable reward functions than prior methods and improves robot learning performance across a diverse set of downstream applications. Code, model weights, and videos at https://robometer.github.io/.
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
ReWiND: Language-Guided Rewards Teach Robot Policies without New Demonstrations
May 16, 2025

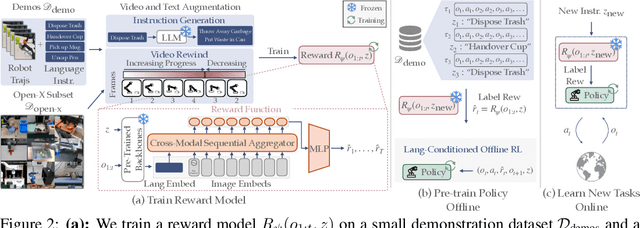
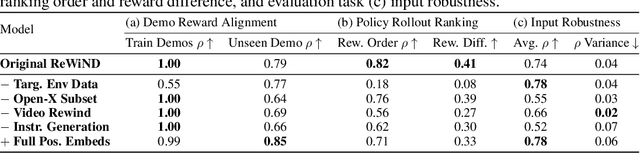
We introduce ReWiND, a framework for learning robot manipulation tasks solely from language instructions without per-task demonstrations. Standard reinforcement learning (RL) and imitation learning methods require expert supervision through human-designed reward functions or demonstrations for every new task. In contrast, ReWiND starts from a small demonstration dataset to learn: (1) a data-efficient, language-conditioned reward function that labels the dataset with rewards, and (2) a language-conditioned policy pre-trained with offline RL using these rewards. Given an unseen task variation, ReWiND fine-tunes the pre-trained policy using the learned reward function, requiring minimal online interaction. We show that ReWiND's reward model generalizes effectively to unseen tasks, outperforming baselines by up to 2.4x in reward generalization and policy alignment metrics. Finally, we demonstrate that ReWiND enables sample-efficient adaptation to new tasks, beating baselines by 2x in simulation and improving real-world pretrained bimanual policies by 5x, taking a step towards scalable, real-world robot learning. See website at https://rewind-reward.github.io/.
Generating Contextually-Relevant Navigation Instructions for Blind and Low Vision People
Jul 11, 2024Navigating unfamiliar environments presents significant challenges for blind and low-vision (BLV) individuals. In this work, we construct a dataset of images and goals across different scenarios such as searching through kitchens or navigating outdoors. We then investigate how grounded instruction generation methods can provide contextually-relevant navigational guidance to users in these instances. Through a sighted user study, we demonstrate that large pretrained language models can produce correct and useful instructions perceived as beneficial for BLV users. We also conduct a survey and interview with 4 BLV users and observe useful insights on preferences for different instructions based on the scenario.
Contrast Sets for Evaluating Language-Guided Robot Policies
Jun 19, 2024
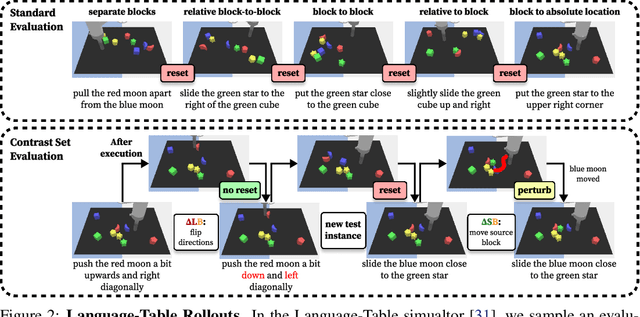
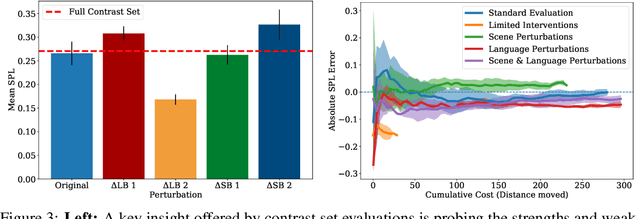

Robot evaluations in language-guided, real world settings are time-consuming and often sample only a small space of potential instructions across complex scenes. In this work, we introduce contrast sets for robotics as an approach to make small, but specific, perturbations to otherwise independent, identically distributed (i.i.d.) test instances. We investigate the relationship between experimenter effort to carry out an evaluation and the resulting estimated test performance as well as the insights that can be drawn from performance on perturbed instances. We use contrast sets to characterize policies at reduced experimenter effort in both a simulated manipulation task and a physical robot vision-and-language navigation task. We encourage the use of contrast set evaluations as a more informative alternative to small scale, i.i.d. demonstrations on physical robots, and as a scalable alternative to industry-scale real world evaluations.
Feel the Bite: Robot-Assisted Inside-Mouth Bite Transfer using Robust Mouth Perception and Physical Interaction-Aware Control
Mar 06, 2024Robot-assisted feeding can greatly enhance the lives of those with mobility limitations. Modern feeding systems can pick up and position food in front of a care recipient's mouth for a bite. However, many with severe mobility constraints cannot lean forward and need direct inside-mouth food placement. This demands precision, especially for those with restricted mouth openings, and appropriately reacting to various physical interactions - incidental contacts as the utensil moves inside, impulsive contacts due to sudden muscle spasms, deliberate tongue maneuvers by the person being fed to guide the utensil, and intentional bites. In this paper, we propose an inside-mouth bite transfer system that addresses these challenges with two key components: a multi-view mouth perception pipeline robust to tool occlusion, and a control mechanism that employs multimodal time-series classification to discern and react to different physical interactions. We demonstrate the efficacy of these individual components through two ablation studies. In a full system evaluation, our system successfully fed 13 care recipients with diverse mobility challenges. Participants consistently emphasized the comfort and safety of our inside-mouth bite transfer system, and gave it high technology acceptance ratings - underscoring its transformative potential in real-world scenarios. Supplementary materials and videos can be found at http://emprise.cs.cornell.edu/bitetransfer/ .
Comparative Multi-View Language Grounding
Nov 14, 2023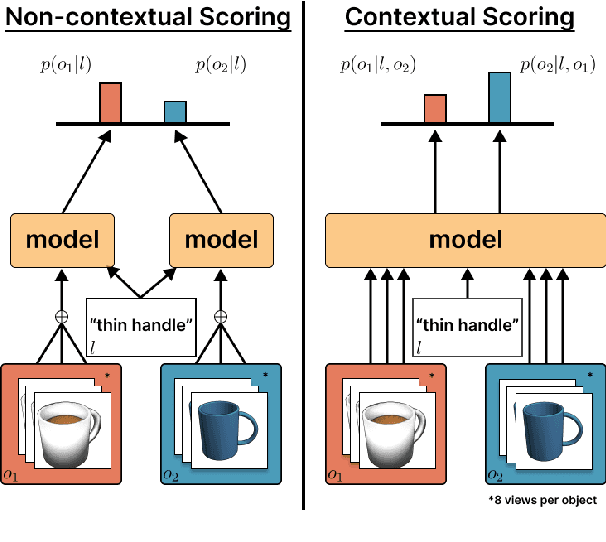
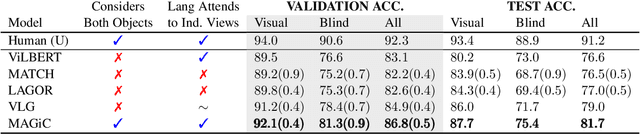

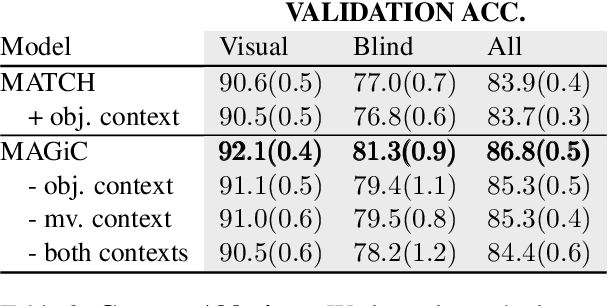
In this work, we consider the task of resolving object referents when given a comparative language description. We present a Multi-view Approach to Grounding in Context (MAGiC) that leverages transformers to pragmatically reason over both objects given multiple image views and a language description. In contrast to past efforts that attempt to connect vision and language for this task without fully considering the resulting referential context, MAGiC makes use of the comparative information by jointly reasoning over multiple views of both object referent candidates and the referring language expression. We present an analysis demonstrating that comparative reasoning contributes to SOTA performance on the SNARE object reference task.
Human-Robot Commensality: Bite Timing Prediction for Robot-Assisted Feeding in Groups
Jul 07, 2022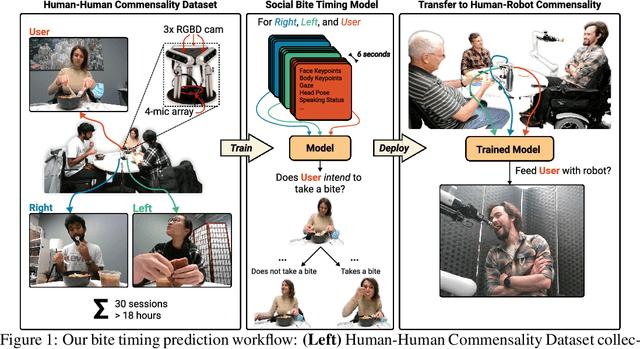
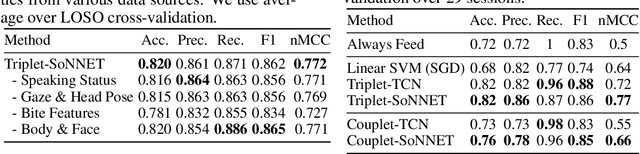
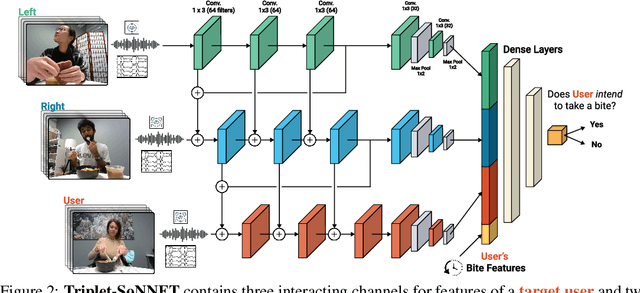
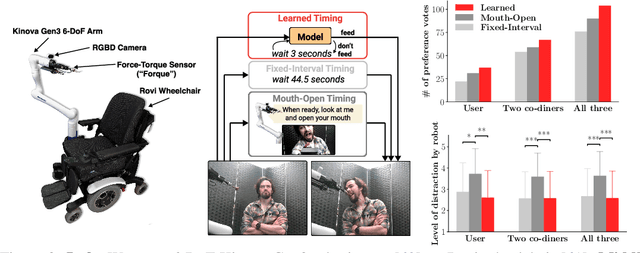
We develop data-driven models to predict when a robot should feed during social dining scenarios. Being able to eat independently with friends and family is considered one of the most memorable and important activities for people with mobility limitations. Robots can potentially help with this activity but robot-assisted feeding is a multi-faceted problem with challenges in bite acquisition, bite timing, and bite transfer. Bite timing in particular becomes uniquely challenging in social dining scenarios due to the possibility of interrupting a social human-robot group interaction during commensality. Our key insight is that bite timing strategies that take into account the delicate balance of social cues can lead to seamless interactions during robot-assisted feeding in a social dining scenario. We approach this problem by collecting a multimodal Human-Human Commensality Dataset (HHCD) containing 30 groups of three people eating together. We use this dataset to analyze human-human commensality behaviors and develop bite timing prediction models in social dining scenarios. We also transfer these models to human-robot commensality scenarios. Our user studies show that prediction improves when our algorithm uses multimodal social signaling cues between diners to model bite timing. The HHCD dataset, videos of user studies, and code will be publicly released after acceptance.