Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Multi-View Language Grounding
Paper and Code
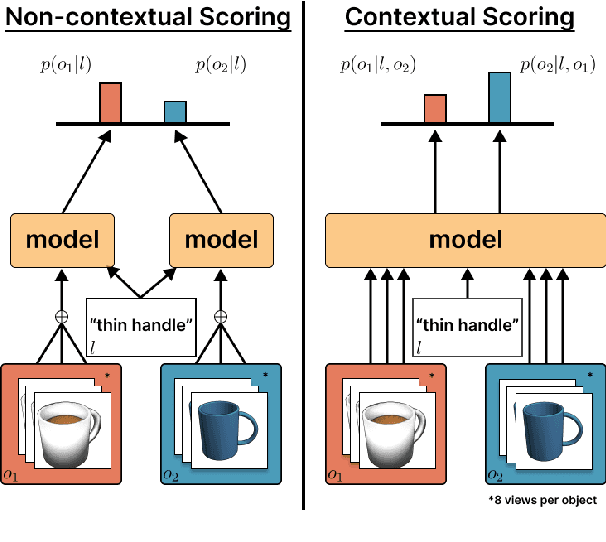
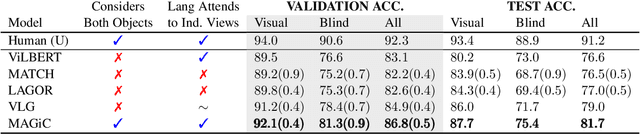

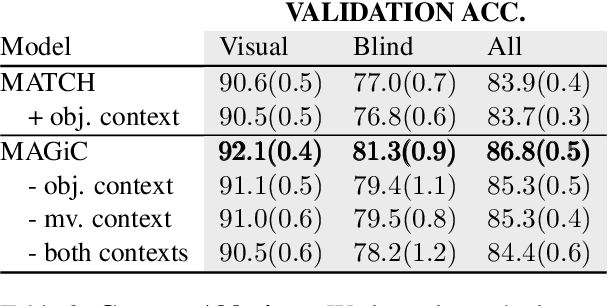
In this work, we consider the task of resolving object referents when given a comparative language description. We present a Multi-view Approach to Grounding in Context (MAGiC) that leverages transformers to pragmatically reason over both objects given multiple image views and a language description. In contrast to past efforts that attempt to connect vision and language for this task without fully considering the resulting referential context, MAGiC makes use of the comparative information by jointly reasoning over multiple views of both object referent candidates and the referring language expression. We present an analysis demonstrating that comparative reasoning contributes to SOTA performance on the SNARE object reference task.
View paper on