 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldValuesBench: A Large-Scale Benchmark Dataset for Multi-Cultural Value Awareness of Language Models
Apr 25, 2024



The awareness of multi-cultural human values is critical to the ability of language models (LMs) to generate safe and personalized responses. However, this awareness of LMs has been insufficiently studied, since the computer science community lacks access to the large-scale real-world data about multi-cultural values. In this paper, we present WorldValuesBench, a globally diverse, large-scale benchmark dataset for the multi-cultural value prediction task, which requires a model to generate a rating response to a value question based on demographic contexts. Our dataset is derived from an influential social science project, World Values Survey (WVS), that has collected answers to hundreds of value questions (e.g., social, economic, ethical) from 94,728 participants worldwide. We have constructed more than 20 million examples of the type "(demographic attributes, value question) $\rightarrow$ answer" from the WVS responses. We perform a case study using our dataset and show that the task is challenging for strong open and closed-source models. On merely $11.1\%$, $25.0\%$, $72.2\%$, and $75.0\%$ of the questions, Alpaca-7B, Vicuna-7B-v1.5, Mixtral-8x7B-Instruct-v0.1, and GPT-3.5 Turbo can respectively achieve $<0.2$ Wasserstein 1-distance from the human normalized answer distributions. WorldValuesBench opens up new research avenues in studying limitations and opportunities in multi-cultural value awareness of LMs.
Understanding Code Semantics: An Evaluation of Transformer Models in Summarization
Oct 27, 2023This paper delves into the intricacies of code summarization using advanced transformer-based language models. Through empirical studies, we evaluate the efficacy of code summarization by altering function and variable names to explore whether models truly understand code semantics or merely rely on textual cues. We have also introduced adversaries like dead code and commented code across three programming languages (Python, Javascript, and Java) to further scrutinize the model's understanding. Ultimately, our research aims to offer valuable insights into the inner workings of transformer-based LMs, enhancing their ability to understand code and contributing to more efficient software development practices and maintenance workflows.
Editing Commonsense Knowledge in GPT
May 24, 2023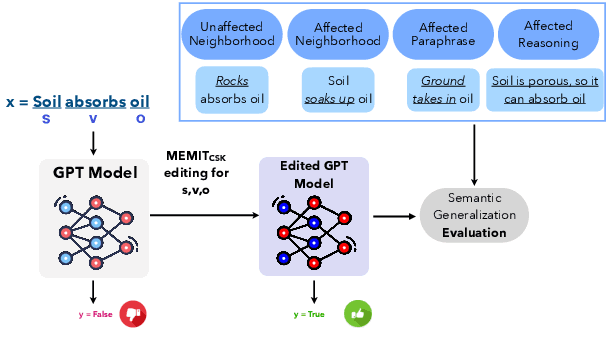
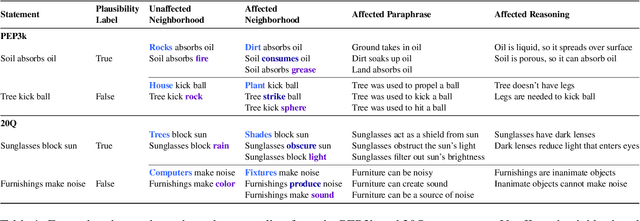
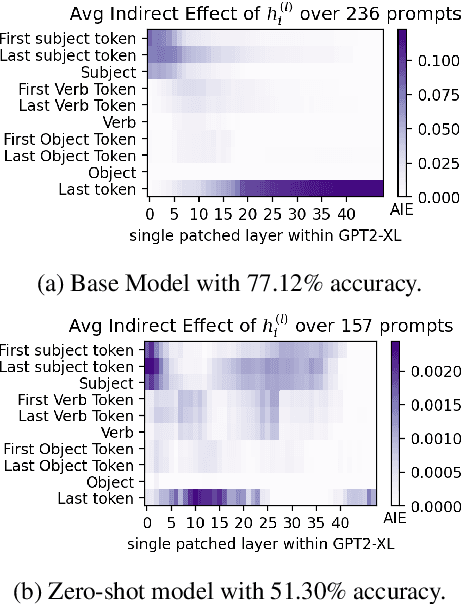
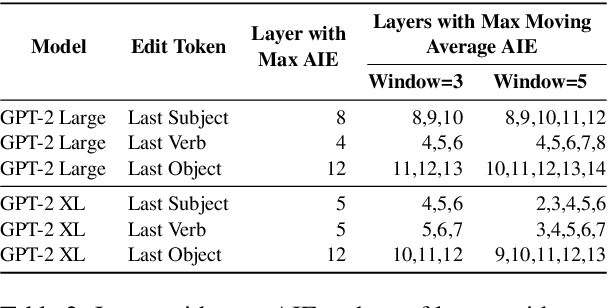
Memory editing methods for updating encyclopedic knowledge in transformers have received increasing attention for their efficacy, specificity, and generalization advantages. However, it remains unclear if such methods can be adapted for the more nuanced domain of commonsense knowledge. We propose $MEMIT_{CSK}$, an adaptation of MEMIT to edit commonsense mistakes in GPT-2 Large and XL. We extend editing to various token locations and employ a robust layer selection strategy. Models edited by $MEMIT_{CSK}$ outperforms the fine-tuning baselines by 10.97% and 10.73% F1 scores on subsets of PEP3k and 20Q. We further propose a novel evaluation dataset, MEMIT-CSK-PROBE, that contains unaffected neighborhood, affected neighborhood, affected paraphrase, and affected reasoning challenges. $MEMIT_{CSK}$ demonstrates favorable semantic generalization, outperforming fine-tuning baselines by 13.72% and 5.57% overall scores on MEMIT-CSK-PROBE. These results suggest a compelling future direction of incorporating context-specific user feedback concerning commonsense in GPT by direct model editing, rectifying and customizing model behaviors via human-in-the-loop systems.