 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Partners in Student Essay Evaluation
Paper and Code
May 28, 2024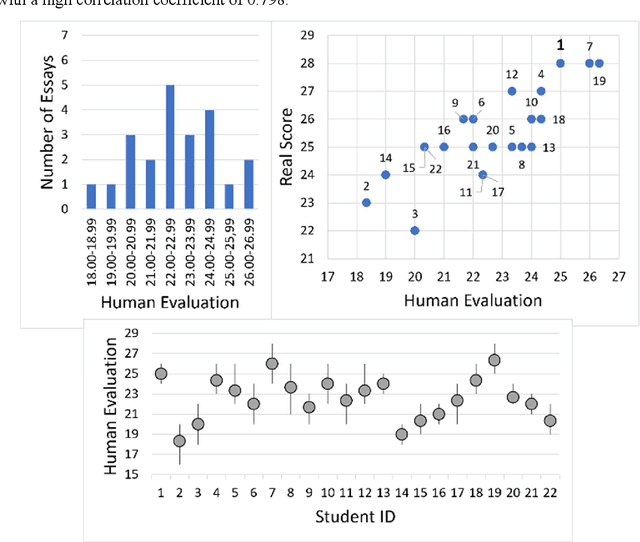

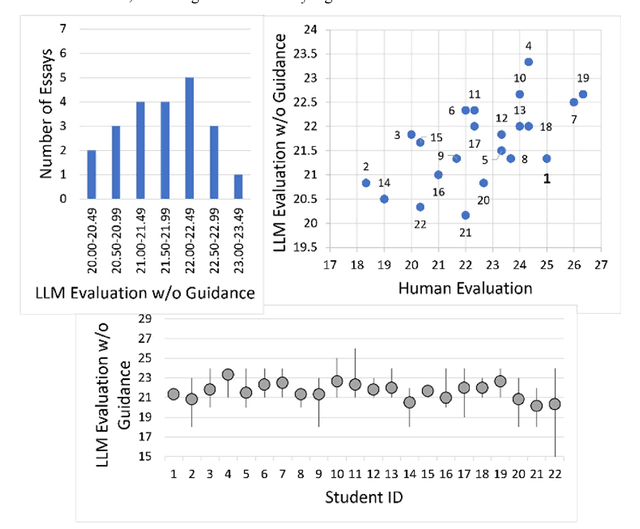
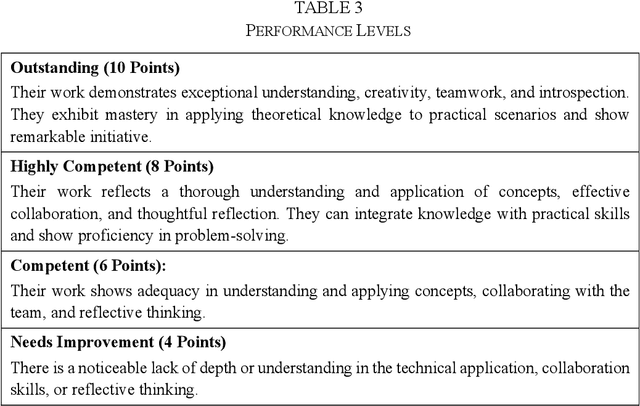
As the importance of comprehensive evaluation in workshop courses increases, there is a growing demand for efficient and fair assessment methods that reduce the workload for faculty members. This paper presents an evaluation conducted with Large Language Models (LLMs) using actual student essays in three scenarios: 1) without providing guidance such as rubrics, 2) with pre-specified rubrics, and 3) through pairwise comparison of essays. Quantitative analysis of the results revealed a strong correlation between LLM and faculty member assessments in the pairwise comparison scenario with pre-specified rubrics, although concerns about the quality and stability of evaluations remained. Therefore, we conducted a qualitative analysis of LLM assessment comments, showing that: 1) LLMs can match the assessment capabilities of faculty members, 2) variations in LLM assessments should be interpreted as diversity rather than confusion, and 3) assessments by humans and LLMs can differ and complement each other. In conclusion, this paper suggests that LLMs should not be seen merely as assistants to faculty members but as partners in evaluation committees and outlines directions for further research.