 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacilitating Holistic Evaluations with LLMs: Insights from Scenario-Based Experiments
May 28, 2024Workshop courses designed to foster creativity are gaining popularity. However, achieving a holistic evaluation that accommodates diverse perspectives is challenging, even for experienced faculty teams. Adequate discussion is essential to integrate varied assessments, but faculty often lack the time for such deliberations. Deriving an average score without discussion undermines the purpose of a holistic evaluation. This paper explores the use of a Large Language Model (LLM) as a facilitator to integrate diverse faculty assessments. Scenario-based experiments were conducted to determine if the LLM could synthesize diverse evaluations and explain the underlying theories to faculty. The results were noteworthy, showing that the LLM effectively facilitated faculty discussions. Additionally, the LLM demonstrated the capability to generalize and create evaluation criteria from a single scenario based on its learned domain knowledge.
Large Language Models as Partners in Student Essay Evaluation
May 28, 2024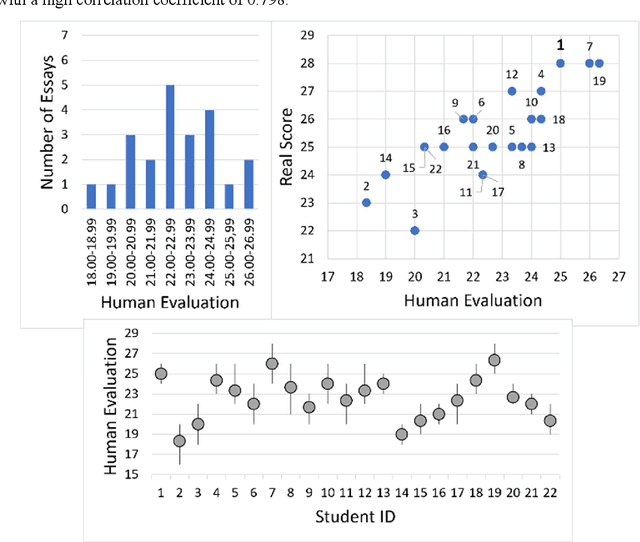

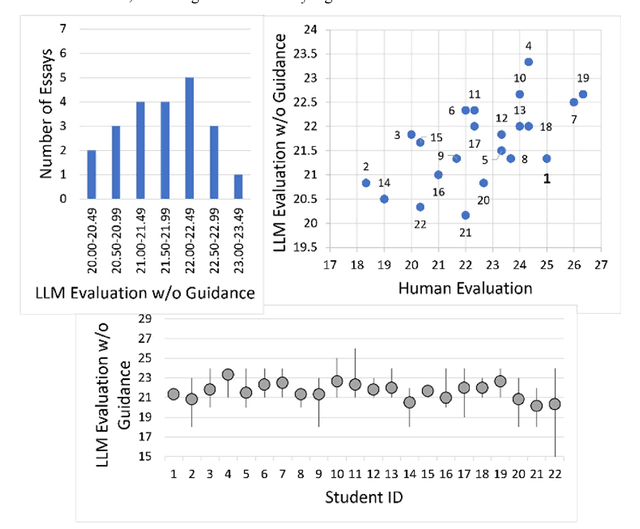
As the importance of comprehensive evaluation in workshop courses increases, there is a growing demand for efficient and fair assessment methods that reduce the workload for faculty members. This paper presents an evaluation conducted with Large Language Models (LLMs) using actual student essays in three scenarios: 1) without providing guidance such as rubrics, 2) with pre-specified rubrics, and 3) through pairwise comparison of essays. Quantitative analysis of the results revealed a strong correlation between LLM and faculty member assessments in the pairwise comparison scenario with pre-specified rubrics, although concerns about the quality and stability of evaluations remained. Therefore, we conducted a qualitative analysis of LLM assessment comments, showing that: 1) LLMs can match the assessment capabilities of faculty members, 2) variations in LLM assessments should be interpreted as diversity rather than confusion, and 3) assessments by humans and LLMs can differ and complement each other. In conclusion, this paper suggests that LLMs should not be seen merely as assistants to faculty members but as partners in evaluation committees and outlines directions for further research.
Plan Optimization to Bilingual Dictionary Induction for Low-Resource Language Families
Oct 05, 2020
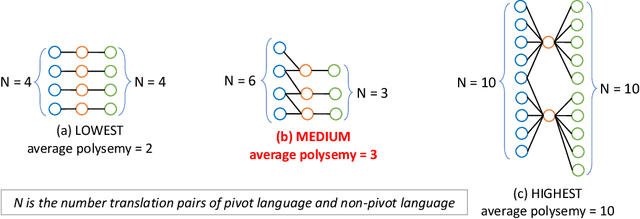
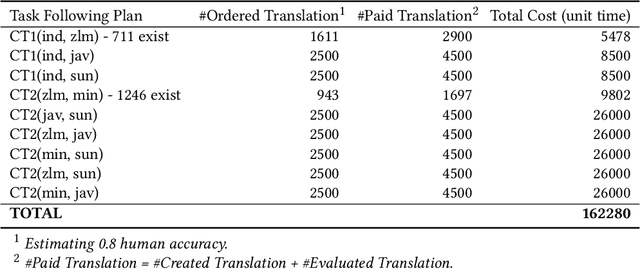
Creating bilingual dictionary is the first crucial step in enriching low-resource languages. Especially for the closely-related ones, it has been shown that the constraint-based approach is useful for inducing bilingual lexicons from two bilingual dictionaries via the pivot language. However, if there are no available machine-readable dictionaries as input, we need to consider manual creation by bilingual native speakers. To reach a goal of comprehensively create multiple bilingual dictionaries, even if we already have several existing machine-readable bilingual dictionaries, it is still difficult to determine the execution order of the constraint-based approach to reducing the total cost. Plan optimization is crucial in composing the order of bilingual dictionaries creation with the consideration of the methods and their costs. We formalize the plan optimization for creating bilingual dictionaries by utilizing Markov Decision Process (MDP) with the goal to get a more accurate estimation of the most feasible optimal plan with the least total cost before fully implementing the constraint-based bilingual lexicon induction. We model a prior beta distribution of bilingual lexicon induction precision with language similarity and polysemy of the topology as $\alpha$ and $\beta$ parameters. It is further used to model cost function and state transition probability. We estimated the cost of all investment plan as a baseline for evaluating the proposed MDP-based approach with total cost as an evaluation metric. After utilizing the posterior beta distribution in the first batch of experiments to construct the prior beta distribution in the second batch of experiments, the result shows 61.5\% of cost reduction compared to the estimated all investment plan and 39.4\% of cost reduction compared to the estimated MDP optimal plan. The MDP-based proposal outperformed the baseline on the total cost.
A Generalized Constraint Approach to Bilingual Dictionary Induction for Low-Resource Language Families
Oct 05, 2020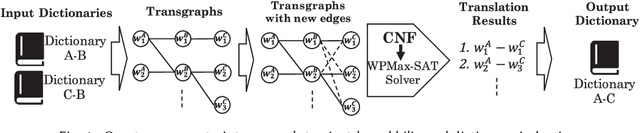



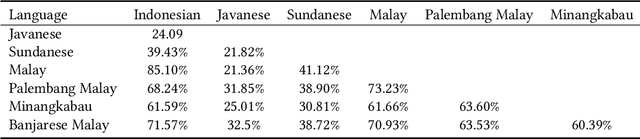
The lack or absence of parallel and comparable corpora makes bilingual lexicon extraction a difficult task for low-resource languages. The pivot language and cognate recognition approaches have been proven useful for inducing bilingual lexicons for such languages. We propose constraint-based bilingual lexicon induction for closely-related languages by extending constraints from the recent pivot-based induction technique and further enabling multiple symmetry assumption cycles to reach many more cognates in the transgraph. We further identify cognate synonyms to obtain many-to-many translation pairs. This paper utilizes four datasets: one Austronesian low-resource language and three Indo-European high-resource languages. We use three constraint-based methods from our previous work, the Inverse Consultation method and translation pairs generated from the Cartesian product of input dictionaries as baselines. We evaluate our result using the metrics of precision, recall and F-score. Our customizable approach allows the user to conduct cross-validation to predict the optimal hyperparameters (cognate threshold and cognate synonym threshold) with various combinations of heuristics and the number of symmetry assumption cycles to gain the highest F-score. Our proposed methods have statistically significant improvement of precision and F-score compared to our previous constraint-based methods. The results show that our method demonstrates the potential to complement other bilingual dictionary creation methods like word alignment models using parallel corpora for high-resource languages while well handling low-resource languages.
* 30 pages, 13 figures, 14 tables, published in ACM TALLIP