 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Retrieval-Augmented Generation in Quranic Studies: A Study of 13 Open-Source Large Language Models
Mar 20, 2025Accurate and contextually faithful responses are critical when applying large language models (LLMs) to sensitive and domain-specific tasks, such as answering queries related to quranic studies. General-purpose LLMs often struggle with hallucinations, where generated responses deviate from authoritative sources, raising concerns about their reliability in religious contexts. This challenge highlights the need for systems that can integrate domain-specific knowledge while maintaining response accuracy, relevance, and faithfulness. In this study, we investigate 13 open-source LLMs categorized into large (e.g., Llama3:70b, Gemma2:27b, QwQ:32b), medium (e.g., Gemma2:9b, Llama3:8b), and small (e.g., Llama3.2:3b, Phi3:3.8b). A Retrieval-Augmented Generation (RAG) is used to make up for the problems that come with using separate models. This research utilizes a descriptive dataset of Quranic surahs including the meanings, historical context, and qualities of the 114 surahs, allowing the model to gather relevant knowledge before responding. The models are evaluated using three key metrics set by human evaluators: context relevance, answer faithfulness, and answer relevance. The findings reveal that large models consistently outperform smaller models in capturing query semantics and producing accurate, contextually grounded responses. The Llama3.2:3b model, even though it is considered small, does very well on faithfulness (4.619) and relevance (4.857), showing the promise of smaller architectures that have been well optimized. This article examines the trade-offs between model size, computational efficiency, and response quality while using LLMs in domain-specific applications.
* 11 pages, keywords: Large-language-models; retrieval-augmented generation; question answering; Quranic studies; Islamic teachings
Plan Optimization to Bilingual Dictionary Induction for Low-Resource Language Families
Oct 05, 2020
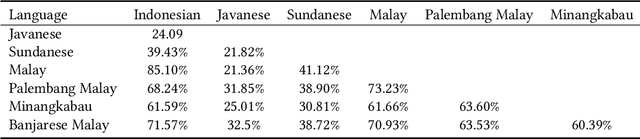
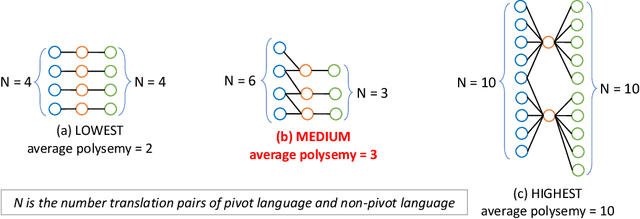
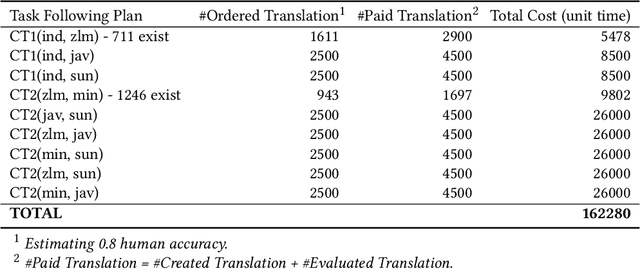
Creating bilingual dictionary is the first crucial step in enriching low-resource languages. Especially for the closely-related ones, it has been shown that the constraint-based approach is useful for inducing bilingual lexicons from two bilingual dictionaries via the pivot language. However, if there are no available machine-readable dictionaries as input, we need to consider manual creation by bilingual native speakers. To reach a goal of comprehensively create multiple bilingual dictionaries, even if we already have several existing machine-readable bilingual dictionaries, it is still difficult to determine the execution order of the constraint-based approach to reducing the total cost. Plan optimization is crucial in composing the order of bilingual dictionaries creation with the consideration of the methods and their costs. We formalize the plan optimization for creating bilingual dictionaries by utilizing Markov Decision Process (MDP) with the goal to get a more accurate estimation of the most feasible optimal plan with the least total cost before fully implementing the constraint-based bilingual lexicon induction. We model a prior beta distribution of bilingual lexicon induction precision with language similarity and polysemy of the topology as $\alpha$ and $\beta$ parameters. It is further used to model cost function and state transition probability. We estimated the cost of all investment plan as a baseline for evaluating the proposed MDP-based approach with total cost as an evaluation metric. After utilizing the posterior beta distribution in the first batch of experiments to construct the prior beta distribution in the second batch of experiments, the result shows 61.5\% of cost reduction compared to the estimated all investment plan and 39.4\% of cost reduction compared to the estimated MDP optimal plan. The MDP-based proposal outperformed the baseline on the total cost.
A Generalized Constraint Approach to Bilingual Dictionary Induction for Low-Resource Language Families
Oct 05, 2020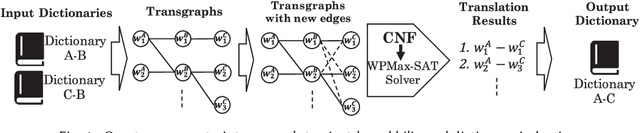



The lack or absence of parallel and comparable corpora makes bilingual lexicon extraction a difficult task for low-resource languages. The pivot language and cognate recognition approaches have been proven useful for inducing bilingual lexicons for such languages. We propose constraint-based bilingual lexicon induction for closely-related languages by extending constraints from the recent pivot-based induction technique and further enabling multiple symmetry assumption cycles to reach many more cognates in the transgraph. We further identify cognate synonyms to obtain many-to-many translation pairs. This paper utilizes four datasets: one Austronesian low-resource language and three Indo-European high-resource languages. We use three constraint-based methods from our previous work, the Inverse Consultation method and translation pairs generated from the Cartesian product of input dictionaries as baselines. We evaluate our result using the metrics of precision, recall and F-score. Our customizable approach allows the user to conduct cross-validation to predict the optimal hyperparameters (cognate threshold and cognate synonym threshold) with various combinations of heuristics and the number of symmetry assumption cycles to gain the highest F-score. Our proposed methods have statistically significant improvement of precision and F-score compared to our previous constraint-based methods. The results show that our method demonstrates the potential to complement other bilingual dictionary creation methods like word alignment models using parallel corpora for high-resource languages while well handling low-resource languages.
* 30 pages, 13 figures, 14 tables, published in ACM TALLIP