 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Retrieval-Augmented Generation in Quranic Studies: A Study of 13 Open-Source Large Language Models
Mar 20, 2025Accurate and contextually faithful responses are critical when applying large language models (LLMs) to sensitive and domain-specific tasks, such as answering queries related to quranic studies. General-purpose LLMs often struggle with hallucinations, where generated responses deviate from authoritative sources, raising concerns about their reliability in religious contexts. This challenge highlights the need for systems that can integrate domain-specific knowledge while maintaining response accuracy, relevance, and faithfulness. In this study, we investigate 13 open-source LLMs categorized into large (e.g., Llama3:70b, Gemma2:27b, QwQ:32b), medium (e.g., Gemma2:9b, Llama3:8b), and small (e.g., Llama3.2:3b, Phi3:3.8b). A Retrieval-Augmented Generation (RAG) is used to make up for the problems that come with using separate models. This research utilizes a descriptive dataset of Quranic surahs including the meanings, historical context, and qualities of the 114 surahs, allowing the model to gather relevant knowledge before responding. The models are evaluated using three key metrics set by human evaluators: context relevance, answer faithfulness, and answer relevance. The findings reveal that large models consistently outperform smaller models in capturing query semantics and producing accurate, contextually grounded responses. The Llama3.2:3b model, even though it is considered small, does very well on faithfulness (4.619) and relevance (4.857), showing the promise of smaller architectures that have been well optimized. This article examines the trade-offs between model size, computational efficiency, and response quality while using LLMs in domain-specific applications.
* 11 pages, keywords: Large-language-models; retrieval-augmented generation; question answering; Quranic studies; Islamic teachings
Towards A Sentiment Analyzer for Low-Resource Languages
Nov 12, 2020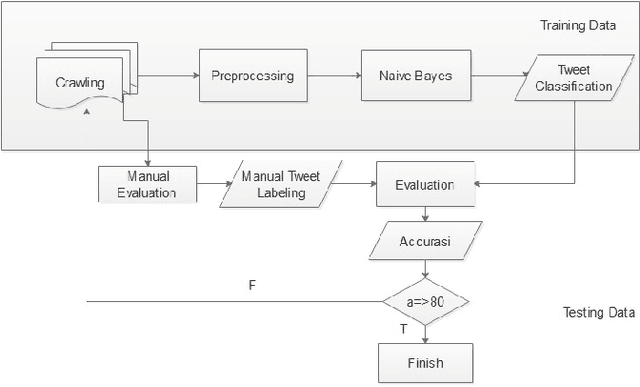
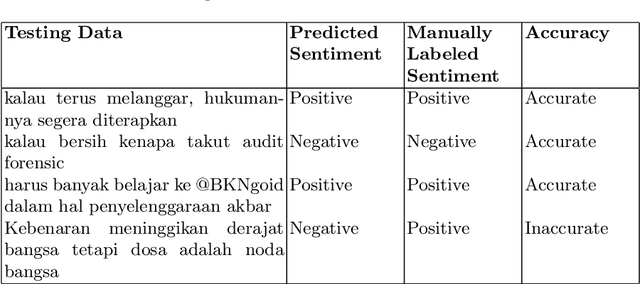


Twitter is one of the top influenced social media which has a million number of active users. It is commonly used for microblogging that allows users to share messages, ideas, thoughts and many more. Thus, millions interaction such as short messages or tweets are flowing around among the twitter users discussing various topics that has been happening world-wide. This research aims to analyse a sentiment of the users towards a particular trending topic that has been actively and massively discussed at that time. We chose a hashtag \textit{\#kpujangancurang} that was the trending topic during the Indonesia presidential election in 2019. We use the hashtag to obtain a set of data from Twitter to analyse and investigate further the positive or the negative sentiment of the users from their tweets. This research utilizes rapid miner tool to generate the twitter data and comparing Naive Bayes, K-Nearest Neighbor, Decision Tree, and Multi-Layer Perceptron classification methods to classify the sentiment of the twitter data. There are overall 200 labeled data in this experiment. Overall, Naive Bayes and Multi-Layer Perceptron classification outperformed the other two methods on 11 experiments with different size of training-testing data split. The two classifiers are potential to be used in creating sentiment analyzer for low-resource languages with small corpus.