 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards well-specified semi-supervised model-based classifiers via structural adaptation
May 01, 2017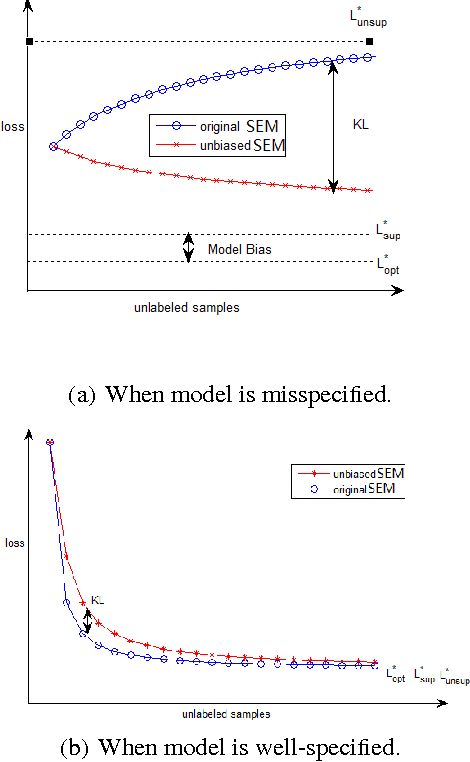
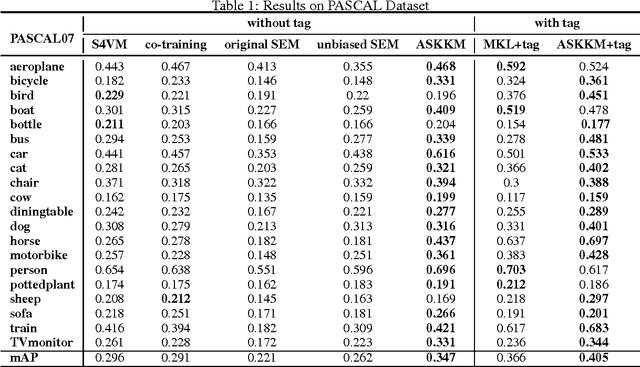
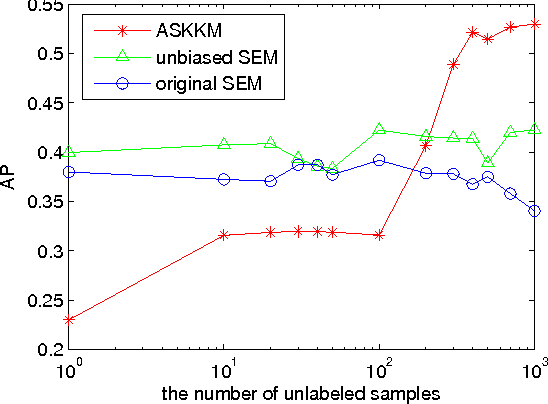
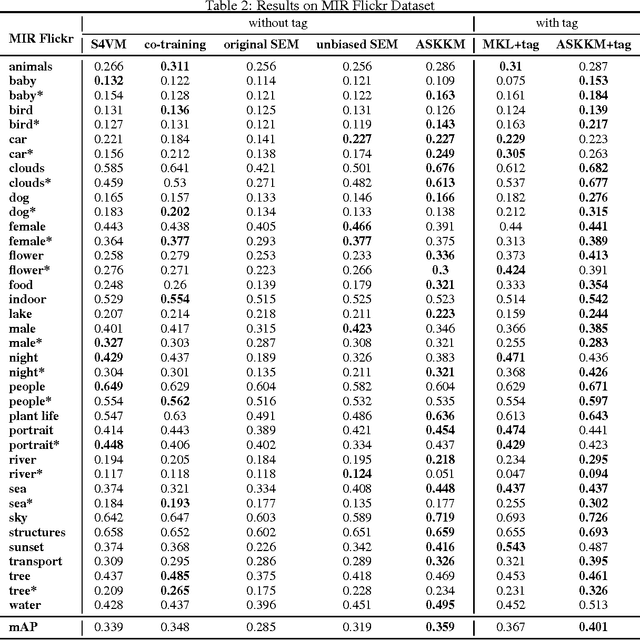
Semi-supervised learning plays an important role in large-scale machine learning. Properly using additional unlabeled data (largely available nowadays) often can improve the machine learning accuracy. However, if the machine learning model is misspecified for the underlying true data distribution, the model performance could be seriously jeopardized. This issue is known as model misspecification. To address this issue, we focus on generative models and propose a criterion to detect the onset of model misspecification by measuring the performance difference between models obtained using supervised and semi-supervised learning. Then, we propose to automatically modify the generative models during model training to achieve an unbiased generative model. Rigorous experiments were carried out to evaluate the proposed method using two image classification data sets PASCAL VOC'07 and MIR Flickr. Our proposed method has been demonstrated to outperform a number of state-of-the-art semi-supervised learning approaches for the classification task.