 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeER-AE: Differentially-private Text Generation for Authorship Anonymization
Sep 10, 2019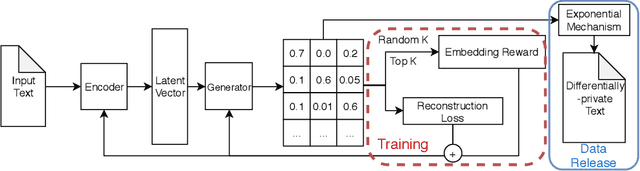
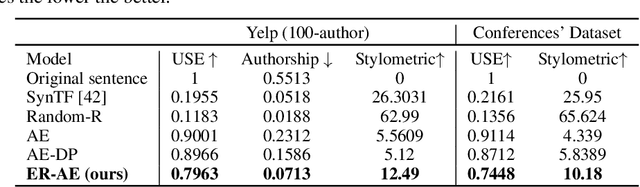

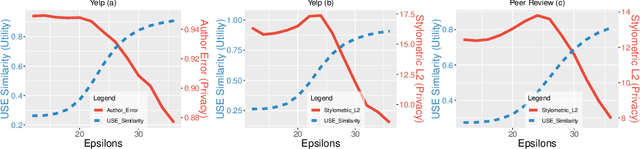
Most of privacy protection studies for textual data focus on removing explicit sensitive identifiers. However, personal writing style, as a strong indicator of the authorship, is often neglected. Recent studies on writing style anonymization can only output numeric vectors which are difficult for the recipients to interpret. We propose a novel text generation model with the exponential mechanism for authorship anonymization. By augmenting the semantic information through a REINFORCE training reward function, the model can generate differentially-private text that has a close semantic and similar grammatical structure to the original text while removing personal traits of the writing style. It does not assume any conditioned labels or paralleled text data for training. We evaluate the performance of the proposed model on the real-life peer reviews dataset and the Yelp review dataset. The result suggests that our model outperforms the state-of-the-art on semantic preservation, authorship obfuscation, and stylometric transformation.