 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Stylometric Representations for Authorship Analysis
Paper and Code
Jun 03, 2016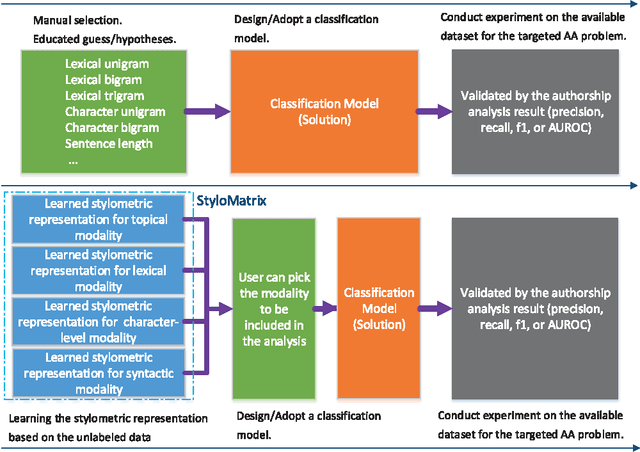
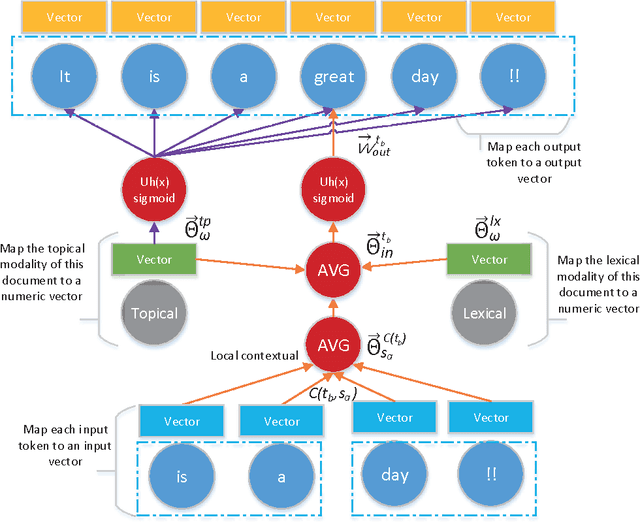
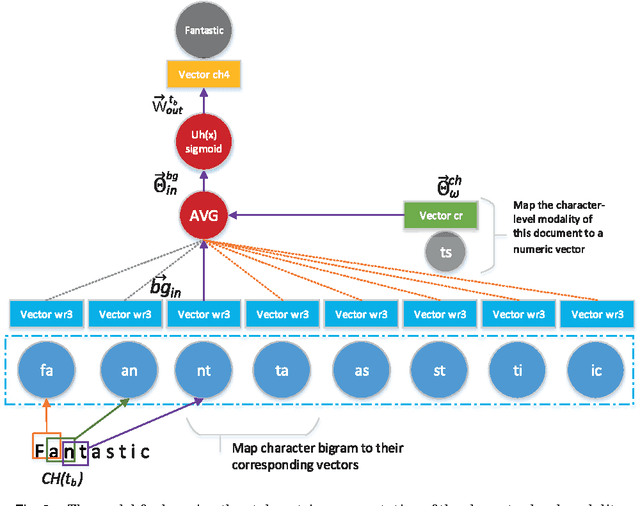
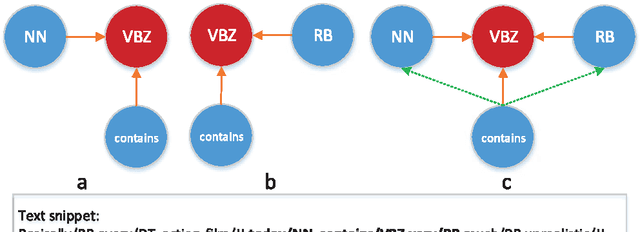
Authorship analysis (AA) is the study of unveiling the hidden properties of authors from a body of exponentially exploding textual data. It extracts an author's identity and sociolinguistic characteristics based on the reflected writing styles in the text. It is an essential process for various areas, such as cybercrime investigation, psycholinguistics, political socialization, etc. However, most of the previous techniques critically depend on the manual feature engineering process. Consequently, the choice of feature set has been shown to be scenario- or dataset-dependent. In this paper, to mimic the human sentence composition process using a neural network approach, we propose to incorporate different categories of linguistic features into distributed representation of words in order to learn simultaneously the writing style representations based on unlabeled texts for authorship analysis. In particular, the proposed models allow topical, lexical, syntactical, and character-level feature vectors of each document to be extracted as stylometrics. We evaluate the performance of our approach on the problems of authorship characterization and authorship verification with the Twitter, novel, and essay datasets. The experiments suggest that our proposed text representation outperforms the bag-of-lexical-n-grams, Latent Dirichlet Allocation, Latent Semantic Analysis, PVDM, PVDBOW, and word2vec representations.