 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbeddings-Based Clustering for Target Specific Stances: The Case of a Polarized Turkey
May 19, 2020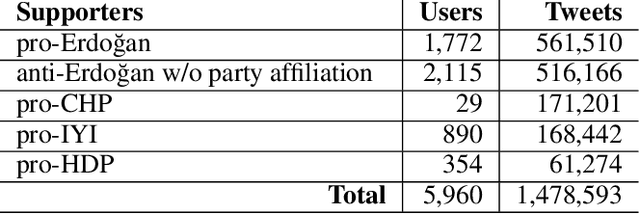
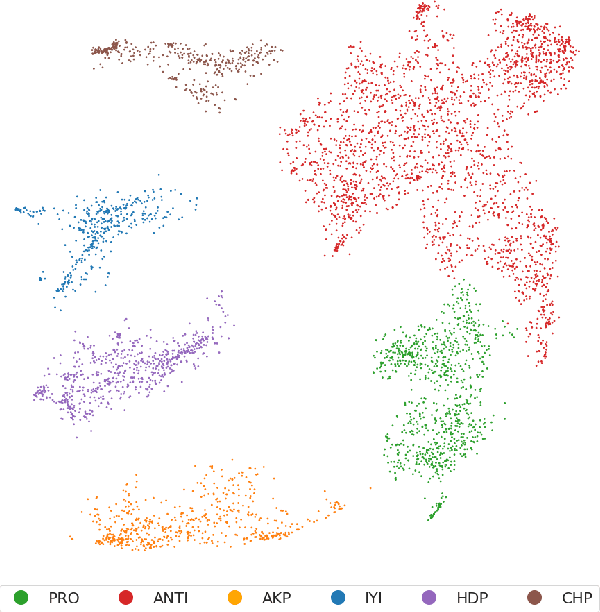
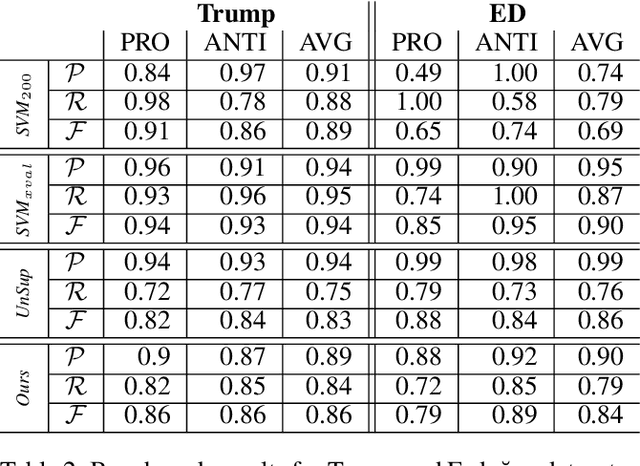
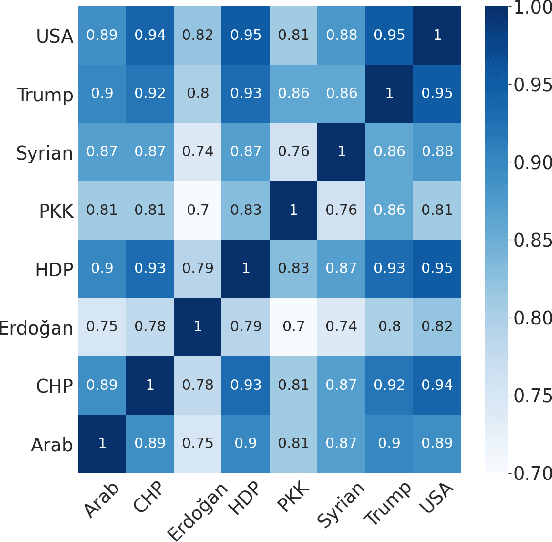
On June 24, 2018, Turkey conducted a highly consequential election in which the Turkish people elected their president and parliament in the first election under a new presidential system. During the election period, the Turkish people extensively shared their political opinions on Twitter. One aspect of polarization among the electorate was support for or opposition to the reelection of Recep Tayyip Erdo\u{g}an. In this paper, we present an unsupervised method for target-specific stance detection in a polarized setting, specifically Turkish politics, achieving 90% precision in identifying user stances, while maintaining more than 80% recall. The method involves representing users in an embedding space using Google's Convolutional Neural Network (CNN) based multilingual universal sentence encoder. The representations are then projected onto a lower dimensional space in a manner that reflects similarities and are consequently clustered. We show the effectiveness of our method in properly clustering users of divergent groups across multiple targets that include political figures, different groups, and parties. We perform our analysis on a large dataset of 108M Turkish election-related tweets along with the timeline tweets of 168k Turkish users, who authored 213M tweets. Given the resultant user stances, we are able to observe correlations between topics and compute topic polarization.
Arabic Offensive Language on Twitter: Analysis and Experiments
Apr 05, 2020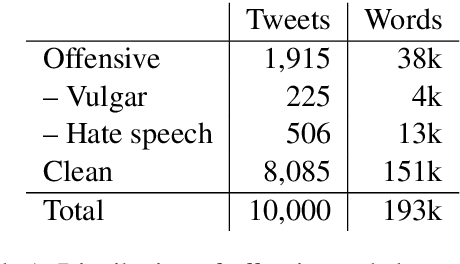
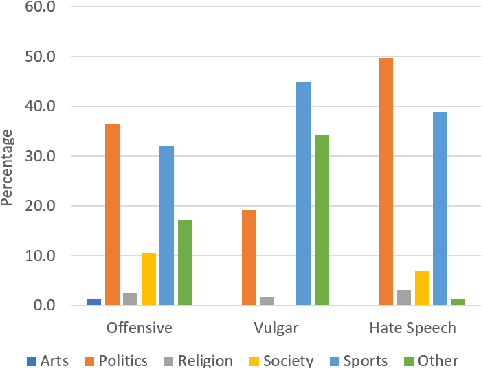
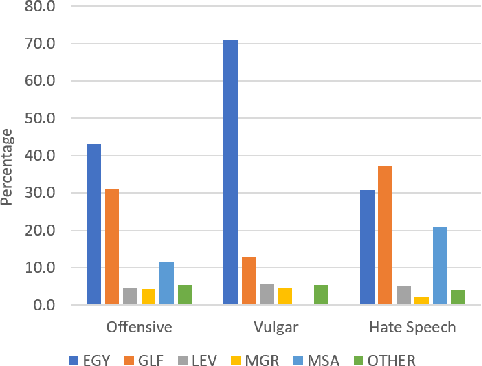
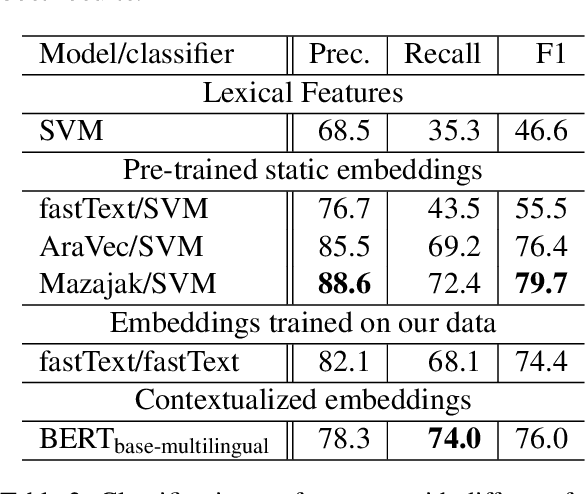
Detecting offensive language on Twitter has many applications ranging from detecting/predicting bullying to measuring polarization. In this paper, we focus on building effective Arabic offensive tweet detection. We introduce a method for building an offensive dataset that is not biased by topic, dialect, or target. We produce the largest Arabic dataset to date with special tags for vulgarity and hate speech. Next, we analyze the dataset to determine which topics, dialects, and gender are most associated with offensive tweets and how Arabic speakers use offensive language. Lastly, we conduct a large battery of experiments to produce strong results (F1 = 79.7) on the dataset using Support Vector Machine techniques.