Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Offensive Language on Twitter: Analysis and Experiments
Paper and Code
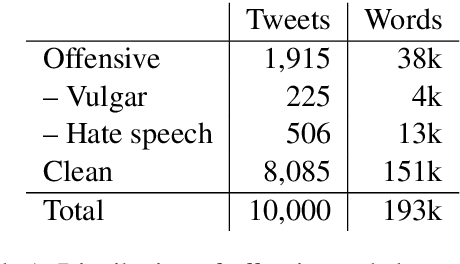
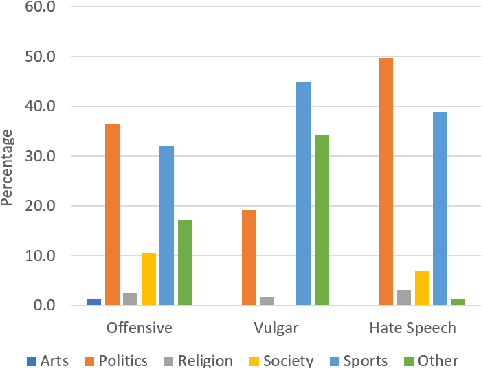
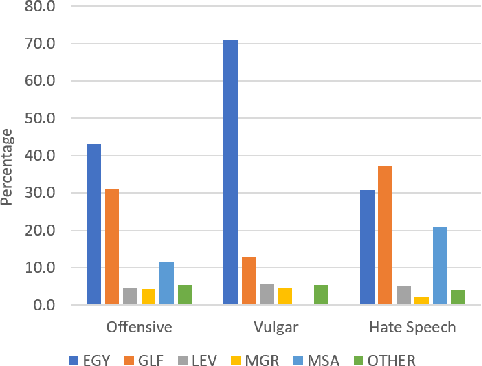
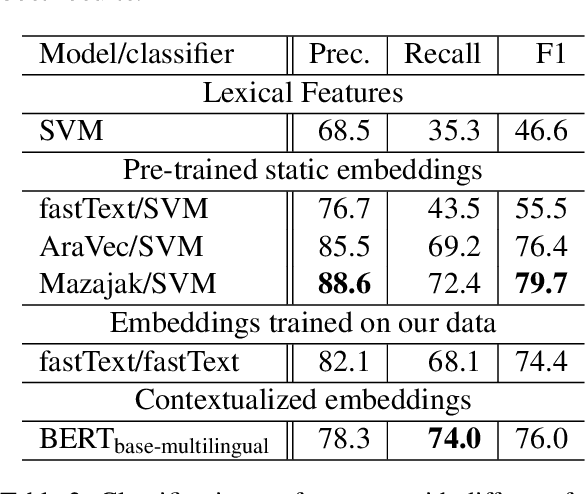
Detecting offensive language on Twitter has many applications ranging from detecting/predicting bullying to measuring polarization. In this paper, we focus on building effective Arabic offensive tweet detection. We introduce a method for building an offensive dataset that is not biased by topic, dialect, or target. We produce the largest Arabic dataset to date with special tags for vulgarity and hate speech. Next, we analyze the dataset to determine which topics, dialects, and gender are most associated with offensive tweets and how Arabic speakers use offensive language. Lastly, we conduct a large battery of experiments to produce strong results (F1 = 79.7) on the dataset using Support Vector Machine techniques.
* 10 pages, 6 figures, 3 tables
View paper on