 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmallify: Learning Network Size while Training
Jun 10, 2018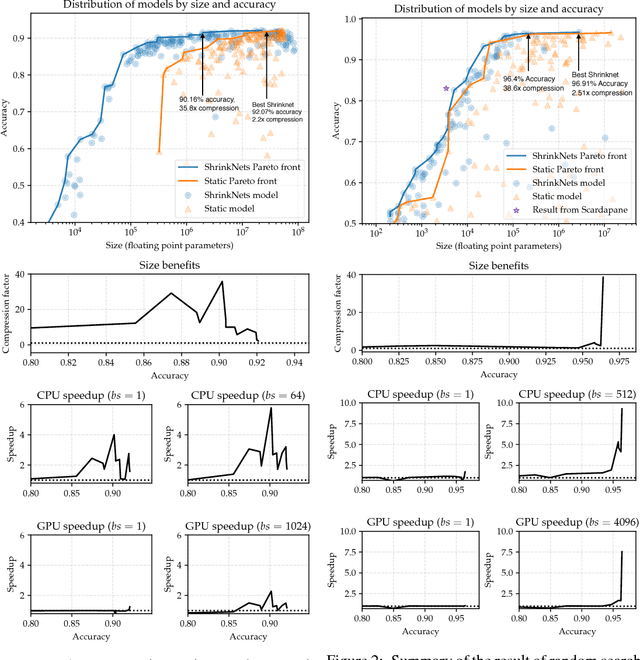
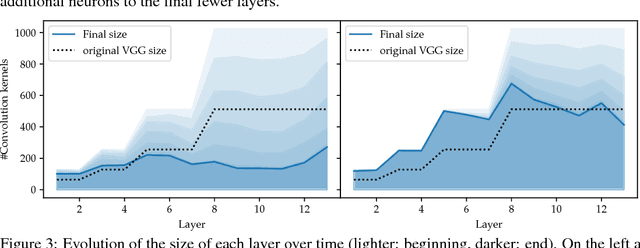
As neural networks become widely deployed in different applications and on different hardware, it has become increasingly important to optimize inference time and model size along with model accuracy. Most current techniques optimize model size, model accuracy and inference time in different stages, resulting in suboptimal results and computational inefficiency. In this work, we propose a new technique called Smallify that optimizes all three of these metrics at the same time. Specifically we present a new method to simultaneously optimize network size and model performance by neuron-level pruning during training. Neuron-level pruning not only produces much smaller networks but also produces dense weight matrices that are amenable to efficient inference. By applying our technique to convolutional as well as fully connected models, we show that Smallify can reduce network size by 35X with a 6X improvement in inference time with similar accuracy as models found by traditional training techniques.