 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddax: Utilizing Zeroth-Order Gradients to Improve Memory Efficiency and Performance of SGD for Fine-Tuning Language Models
Paper and Code
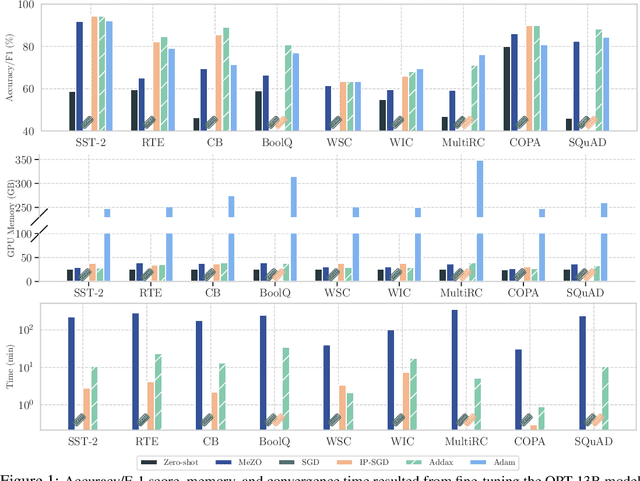

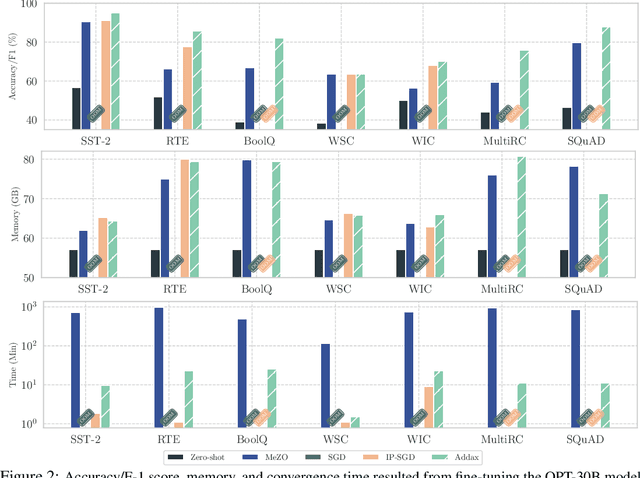

Fine-tuning language models (LMs) with the Adam optimizer often demands excessive memory, limiting accessibility. The "in-place" version of Stochastic Gradient Descent (IP-SGD) and Memory-Efficient Zeroth-order Optimizer (MeZO) have been proposed to address this. However, IP-SGD still requires substantial memory, and MeZO suffers from slow convergence and degraded final performance due to its zeroth-order nature. This paper introduces Addax, a novel method that improves both memory efficiency and performance of IP-SGD by integrating it with MeZO. Specifically, Addax computes zeroth- or first-order gradients of data points in the minibatch based on their memory consumption, combining these gradient estimates to update directions. By computing zeroth-order gradients for data points that require more memory and first-order gradients for others, Addax overcomes the slow convergence of MeZO and the excessive memory requirement of IP-SGD. Additionally, the zeroth-order gradient acts as a regularizer for the first-order gradient, further enhancing the model's final performance. Theoretically, we establish the convergence of Addax under mild assumptions, demonstrating faster convergence and less restrictive hyper-parameter choices than MeZO. Our experiments with diverse LMs and tasks show that Addax consistently outperforms MeZO regarding accuracy and convergence speed while having a comparable memory footprint. When fine-tuning OPT-13B with one A100 GPU, on average, Addax outperforms MeZO in accuracy/F1 score by 14% and runs 15x faster while using memory similar to MeZO. In our experiments on the larger OPT-30B model, on average, Addax outperforms MeZO in terms of accuracy/F1 score by >16 and runs 30x faster on a single H100 GPU. Moreover, Addax surpasses the performance of standard fine-tuning approaches, such as IP-SGD and Adam, in most tasks with significantly less memory requirement.