 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Embedded 3D Gaussians for Open-Vocabulary Scene Understanding
Nov 30, 2023



Open-vocabulary querying in 3D space is challenging but essential for scene understanding tasks such as object localization and segmentation. Language-embedded scene representations have made progress by incorporating language features into 3D spaces. However, their efficacy heavily depends on neural networks that are resource-intensive in training and rendering. Although recent 3D Gaussians offer efficient and high-quality novel view synthesis, directly embedding language features in them leads to prohibitive memory usage and decreased performance. In this work, we introduce Language Embedded 3D Gaussians, a novel scene representation for open-vocabulary query tasks. Instead of embedding high-dimensional raw semantic features on 3D Gaussians, we propose a dedicated quantization scheme that drastically alleviates the memory requirement, and a novel embedding procedure that achieves smoother yet high accuracy query, countering the multi-view feature inconsistencies and the high-frequency inductive bias in point-based representations. Our comprehensive experiments show that our representation achieves the best visual quality and language querying accuracy across current language-embedded representations, while maintaining real-time rendering frame rates on a single desktop GPU.
BakedAvatar: Baking Neural Fields for Real-Time Head Avatar Synthesis
Nov 28, 2023Synthesizing photorealistic 4D human head avatars from videos is essential for VR/AR, telepresence, and video game applications. Although existing Neural Radiance Fields (NeRF)-based methods achieve high-fidelity results, the computational expense limits their use in real-time applications. To overcome this limitation, we introduce BakedAvatar, a novel representation for real-time neural head avatar synthesis, deployable in a standard polygon rasterization pipeline. Our approach extracts deformable multi-layer meshes from learned isosurfaces of the head and computes expression-, pose-, and view-dependent appearances that can be baked into static textures for efficient rasterization. We thus propose a three-stage pipeline for neural head avatar synthesis, which includes learning continuous deformation, manifold, and radiance fields, extracting layered meshes and textures, and fine-tuning texture details with differential rasterization. Experimental results demonstrate that our representation generates synthesis results of comparable quality to other state-of-the-art methods while significantly reducing the inference time required. We further showcase various head avatar synthesis results from monocular videos, including view synthesis, face reenactment, expression editing, and pose editing, all at interactive frame rates.
* ACM Transactions on Graphics (SIGGRAPH Asia 2023). Project Page: https://buaavrcg.github.io/BakedAvatar
PaintNeSF: Artistic Creation of Stylized Scenes with Vectorized 3D Strokes
Nov 27, 2023We present Paint Neural Stroke Field (PaintNeSF), a novel technique to generate stylized images of a 3D scene at arbitrary novel views from multi-view 2D images. Different from existing methods which apply stylization to trained neural radiance fields at the voxel level, our approach draws inspiration from image-to-painting methods, simulating the progressive painting process of human artwork with vector strokes. We develop a palette of stylized 3D strokes from basic primitives and splines, and consider the 3D scene stylization task as a multi-view reconstruction process based on these 3D stroke primitives. Instead of directly searching for the parameters of these 3D strokes, which would be too costly, we introduce a differentiable renderer that allows optimizing stroke parameters using gradient descent, and propose a training scheme to alleviate the vanishing gradient issue. The extensive evaluation demonstrates that our approach effectively synthesizes 3D scenes with significant geometric and aesthetic stylization while maintaining a consistent appearance across different views. Our method can be further integrated with style loss and image-text contrastive models to extend its applications, including color transfer and text-driven 3D scene drawing.
HoughLaneNet: Lane Detection with Deep Hough Transform and Dynamic Convolution
Jul 07, 2023
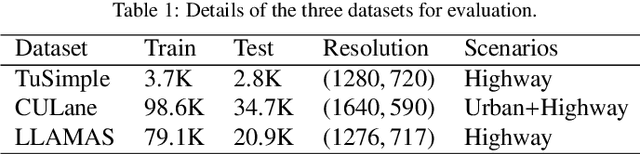

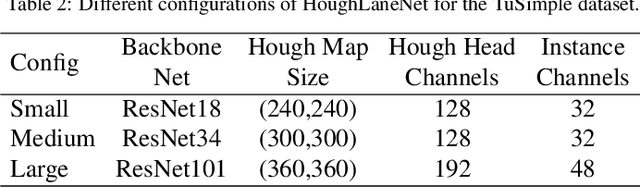
The task of lane detection has garnered considerable attention in the field of autonomous driving due to its complexity. Lanes can present difficulties for detection, as they can be narrow, fragmented, and often obscured by heavy traffic. However, it has been observed that the lanes have a geometrical structure that resembles a straight line, leading to improved lane detection results when utilizing this characteristic. To address this challenge, we propose a hierarchical Deep Hough Transform (DHT) approach that combines all lane features in an image into the Hough parameter space. Additionally, we refine the point selection method and incorporate a Dynamic Convolution Module to effectively differentiate between lanes in the original image. Our network architecture comprises a backbone network, either a ResNet or Pyramid Vision Transformer, a Feature Pyramid Network as the neck to extract multi-scale features, and a hierarchical DHT-based feature aggregation head to accurately segment each lane. By utilizing the lane features in the Hough parameter space, the network learns dynamic convolution kernel parameters corresponding to each lane, allowing the Dynamic Convolution Module to effectively differentiate between lane features. Subsequently, the lane features are fed into the feature decoder, which predicts the final position of the lane. Our proposed network structure demonstrates improved performance in detecting heavily occluded or worn lane images, as evidenced by our extensive experimental results, which show that our method outperforms or is on par with state-of-the-art techniques.