 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGILE: Hand-Object Interaction Reconstruction from Video via Agentic Generation
Feb 04, 2026Reconstructing dynamic hand-object interactions from monocular videos is critical for dexterous manipulation data collection and creating realistic digital twins for robotics and VR. However, current methods face two prohibitive barriers: (1) reliance on neural rendering often yields fragmented, non-simulation-ready geometries under heavy occlusion, and (2) dependence on brittle Structure-from-Motion (SfM) initialization leads to frequent failures on in-the-wild footage. To overcome these limitations, we introduce AGILE, a robust framework that shifts the paradigm from reconstruction to agentic generation for interaction learning. First, we employ an agentic pipeline where a Vision-Language Model (VLM) guides a generative model to synthesize a complete, watertight object mesh with high-fidelity texture, independent of video occlusions. Second, bypassing fragile SfM entirely, we propose a robust anchor-and-track strategy. We initialize the object pose at a single interaction onset frame using a foundation model and propagate it temporally by leveraging the strong visual similarity between our generated asset and video observations. Finally, a contact-aware optimization integrates semantic, geometric, and interaction stability constraints to enforce physical plausibility. Extensive experiments on HO3D, DexYCB, and in-the-wild videos reveal that AGILE outperforms baselines in global geometric accuracy while demonstrating exceptional robustness on challenging sequences where prior art frequently collapses. By prioritizing physical validity, our method produces simulation-ready assets validated via real-to-sim retargeting for robotic applications.
Mono4DEditor: Text-Driven 4D Scene Editing from Monocular Video via Point-Level Localization of Language-Embedded Gaussians
Oct 10, 2025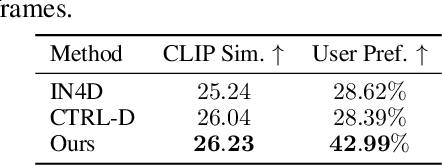
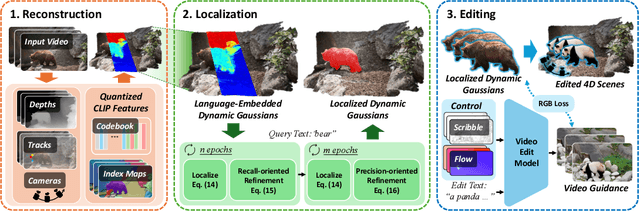
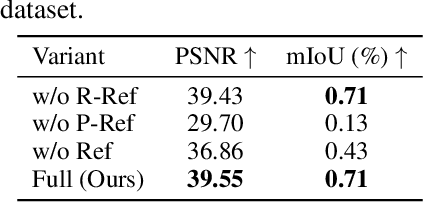

Editing 4D scenes reconstructed from monocular videos based on text prompts is a valuable yet challenging task with broad applications in content creation and virtual environments. The key difficulty lies in achieving semantically precise edits in localized regions of complex, dynamic scenes, while preserving the integrity of unedited content. To address this, we introduce Mono4DEditor, a novel framework for flexible and accurate text-driven 4D scene editing. Our method augments 3D Gaussians with quantized CLIP features to form a language-embedded dynamic representation, enabling efficient semantic querying of arbitrary spatial regions. We further propose a two-stage point-level localization strategy that first selects candidate Gaussians via CLIP similarity and then refines their spatial extent to improve accuracy. Finally, targeted edits are performed on localized regions using a diffusion-based video editing model, with flow and scribble guidance ensuring spatial fidelity and temporal coherence. Extensive experiments demonstrate that Mono4DEditor enables high-quality, text-driven edits across diverse scenes and object types, while preserving the appearance and geometry of unedited areas and surpassing prior approaches in both flexibility and visual fidelity.
Language Embedded 3D Gaussians for Open-Vocabulary Scene Understanding
Nov 30, 2023



Open-vocabulary querying in 3D space is challenging but essential for scene understanding tasks such as object localization and segmentation. Language-embedded scene representations have made progress by incorporating language features into 3D spaces. However, their efficacy heavily depends on neural networks that are resource-intensive in training and rendering. Although recent 3D Gaussians offer efficient and high-quality novel view synthesis, directly embedding language features in them leads to prohibitive memory usage and decreased performance. In this work, we introduce Language Embedded 3D Gaussians, a novel scene representation for open-vocabulary query tasks. Instead of embedding high-dimensional raw semantic features on 3D Gaussians, we propose a dedicated quantization scheme that drastically alleviates the memory requirement, and a novel embedding procedure that achieves smoother yet high accuracy query, countering the multi-view feature inconsistencies and the high-frequency inductive bias in point-based representations. Our comprehensive experiments show that our representation achieves the best visual quality and language querying accuracy across current language-embedded representations, while maintaining real-time rendering frame rates on a single desktop GPU.
BakedAvatar: Baking Neural Fields for Real-Time Head Avatar Synthesis
Nov 28, 2023Synthesizing photorealistic 4D human head avatars from videos is essential for VR/AR, telepresence, and video game applications. Although existing Neural Radiance Fields (NeRF)-based methods achieve high-fidelity results, the computational expense limits their use in real-time applications. To overcome this limitation, we introduce BakedAvatar, a novel representation for real-time neural head avatar synthesis, deployable in a standard polygon rasterization pipeline. Our approach extracts deformable multi-layer meshes from learned isosurfaces of the head and computes expression-, pose-, and view-dependent appearances that can be baked into static textures for efficient rasterization. We thus propose a three-stage pipeline for neural head avatar synthesis, which includes learning continuous deformation, manifold, and radiance fields, extracting layered meshes and textures, and fine-tuning texture details with differential rasterization. Experimental results demonstrate that our representation generates synthesis results of comparable quality to other state-of-the-art methods while significantly reducing the inference time required. We further showcase various head avatar synthesis results from monocular videos, including view synthesis, face reenactment, expression editing, and pose editing, all at interactive frame rates.
* ACM Transactions on Graphics (SIGGRAPH Asia 2023). Project Page: https://buaavrcg.github.io/BakedAvatar