 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Deja-vu: Creating Controllable 3D Gaussian Head-Avatars with Enhanced Generalization and Personalization Abilities
Sep 26, 2024
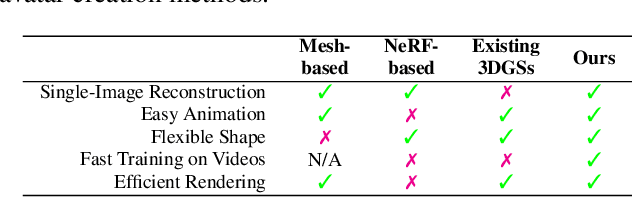


Recent advancements in 3D Gaussian Splatting (3DGS) have unlocked significant potential for modeling 3D head avatars, providing greater flexibility than mesh-based methods and more efficient rendering compared to NeRF-based approaches. Despite these advancements, the creation of controllable 3DGS-based head avatars remains time-intensive, often requiring tens of minutes to hours. To expedite this process, we here introduce the ``Gaussian D\'ej\`a-vu" framework, which first obtains a generalized model of the head avatar and then personalizes the result. The generalized model is trained on large 2D (synthetic and real) image datasets. This model provides a well-initialized 3D Gaussian head that is further refined using a monocular video to achieve the personalized head avatar. For personalizing, we propose learnable expression-aware rectification blendmaps to correct the initial 3D Gaussians, ensuring rapid convergence without the reliance on neural networks. Experiments demonstrate that the proposed method meets its objectives. It outperforms state-of-the-art 3D Gaussian head avatars in terms of photorealistic quality as well as reduces training time consumption to at least a quarter of the existing methods, producing the avatar in minutes.
PoseGen: Learning to Generate 3D Human Pose Dataset with NeRF
Dec 22, 2023This paper proposes an end-to-end framework for generating 3D human pose datasets using Neural Radiance Fields (NeRF). Public datasets generally have limited diversity in terms of human poses and camera viewpoints, largely due to the resource-intensive nature of collecting 3D human pose data. As a result, pose estimators trained on public datasets significantly underperform when applied to unseen out-of-distribution samples. Previous works proposed augmenting public datasets by generating 2D-3D pose pairs or rendering a large amount of random data. Such approaches either overlook image rendering or result in suboptimal datasets for pre-trained models. Here we propose PoseGen, which learns to generate a dataset (human 3D poses and images) with a feedback loss from a given pre-trained pose estimator. In contrast to prior art, our generated data is optimized to improve the robustness of the pre-trained model. The objective of PoseGen is to learn a distribution of data that maximizes the prediction error of a given pre-trained model. As the learned data distribution contains OOD samples of the pre-trained model, sampling data from such a distribution for further fine-tuning a pre-trained model improves the generalizability of the model. This is the first work that proposes NeRFs for 3D human data generation. NeRFs are data-driven and do not require 3D scans of humans. Therefore, using NeRF for data generation is a new direction for convenient user-specific data generation. Our extensive experiments show that the proposed PoseGen improves two baseline models (SPIN and HybrIK) on four datasets with an average 6% relative improvement.
Multi-modal Streaming 3D Object Detection
Sep 12, 2022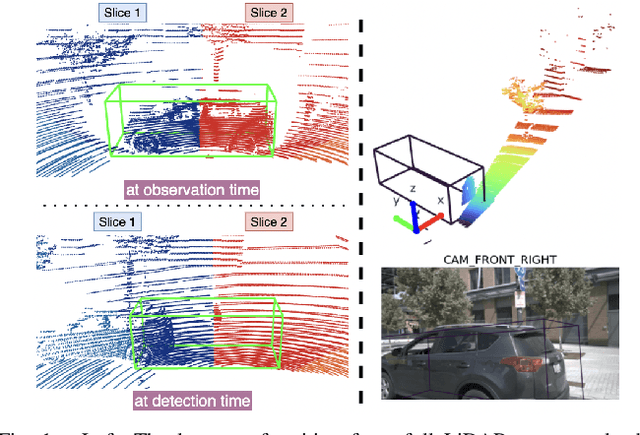
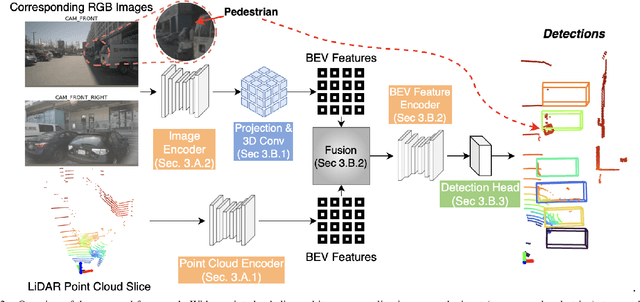
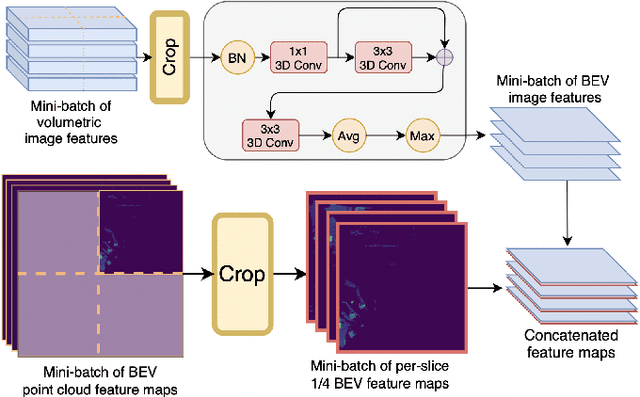

Modern autonomous vehicles rely heavily on mechanical LiDARs for perception. Current perception methods generally require 360{\deg} point clouds, collected sequentially as the LiDAR scans the azimuth and acquires consecutive wedge-shaped slices. The acquisition latency of a full scan (~ 100ms) may lead to outdated perception which is detrimental to safe operation. Recent streaming perception works proposed directly processing LiDAR slices and compensating for the narrow field of view (FOV) of a slice by reusing features from preceding slices. These works, however, are all based on a single modality and require past information which may be outdated. Meanwhile, images from high-frequency cameras can support streaming models as they provide a larger FoV compared to a LiDAR slice. However, this difference in FoV complicates sensor fusion. To address this research gap, we propose an innovative camera-LiDAR streaming 3D object detection framework that uses camera images instead of past LiDAR slices to provide an up-to-date, dense, and wide context for streaming perception. The proposed method outperforms prior streaming models on the challenging NuScenes benchmark. It also outperforms powerful full-scan detectors while being much faster. Our method is shown to be robust to missing camera images, narrow LiDAR slices, and small camera-LiDAR miscalibration.
AdaptPose: Cross-Dataset Adaptation for 3D Human Pose Estimation by Learnable Motion Generation
Dec 22, 2021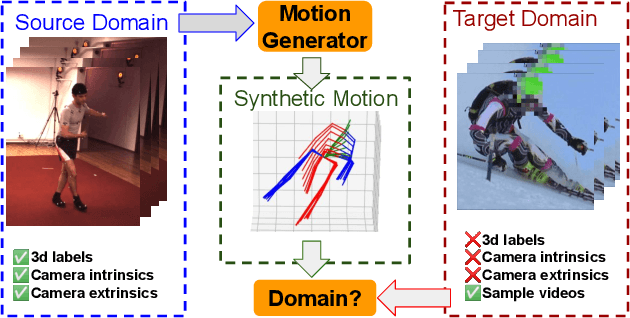
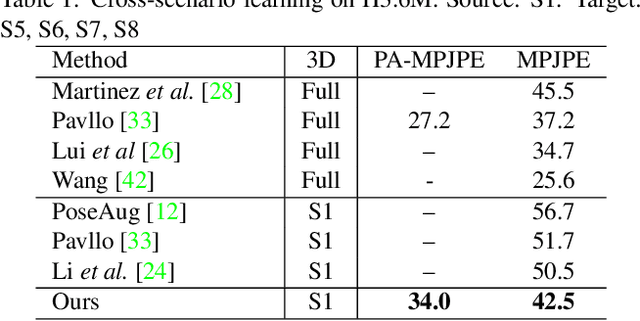
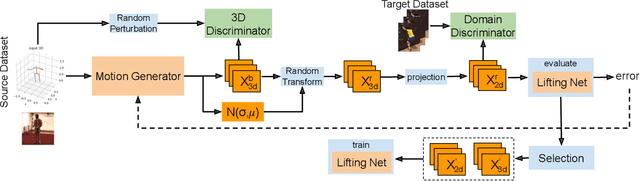
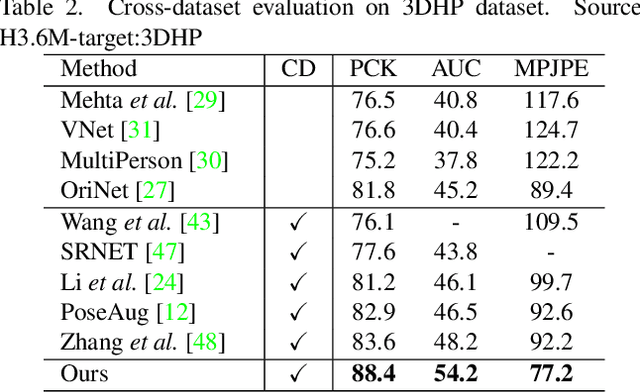
This paper addresses the problem of cross-dataset generalization of 3D human pose estimation models. Testing a pre-trained 3D pose estimator on a new dataset results in a major performance drop. Previous methods have mainly addressed this problem by improving the diversity of the training data. We argue that diversity alone is not sufficient and that the characteristics of the training data need to be adapted to those of the new dataset such as camera viewpoint, position, human actions, and body size. To this end, we propose AdaptPose, an end-to-end framework that generates synthetic 3D human motions from a source dataset and uses them to fine-tune a 3D pose estimator. AdaptPose follows an adversarial training scheme. From a source 3D pose the generator generates a sequence of 3D poses and a camera orientation that is used to project the generated poses to a novel view. Without any 3D labels or camera information AdaptPose successfully learns to create synthetic 3D poses from the target dataset while only being trained on 2D poses. In experiments on the Human3.6M, MPI-INF-3DHP, 3DPW, and Ski-Pose datasets our method outperforms previous work in cross-dataset evaluations by 14% and previous semi-supervised learning methods that use partial 3D annotations by 16%.
TriPose: A Weakly-Supervised 3D Human Pose Estimation via Triangulation from Video
May 14, 2021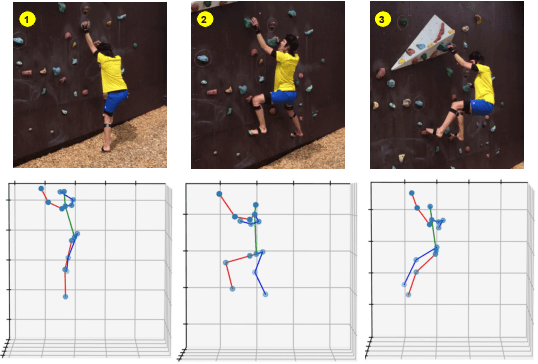
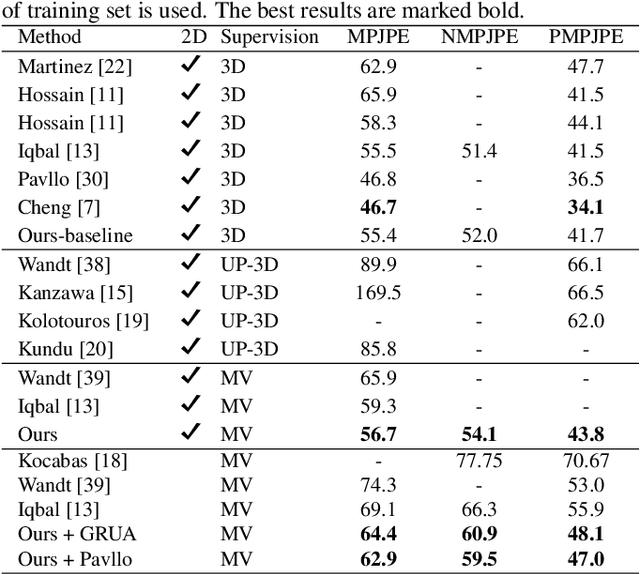
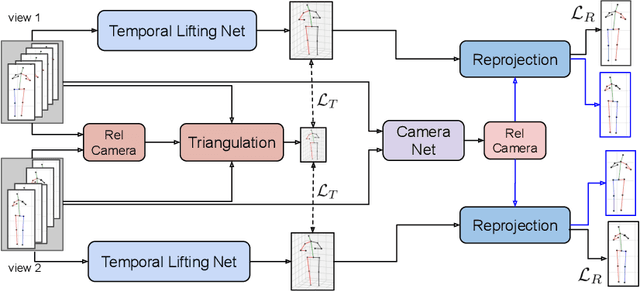
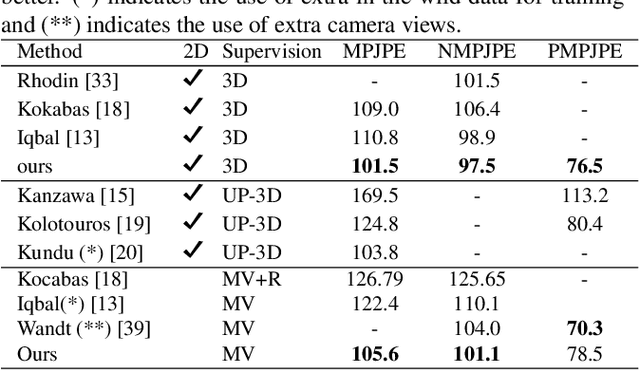
Estimating 3D human poses from video is a challenging problem. The lack of 3D human pose annotations is a major obstacle for supervised training and for generalization to unseen datasets. In this work, we address this problem by proposing a weakly-supervised training scheme that does not require 3D annotations or calibrated cameras. The proposed method relies on temporal information and triangulation. Using 2D poses from multiple views as the input, we first estimate the relative camera orientations and then generate 3D poses via triangulation. The triangulation is only applied to the views with high 2D human joint confidence. The generated 3D poses are then used to train a recurrent lifting network (RLN) that estimates 3D poses from 2D poses. We further apply a multi-view re-projection loss to the estimated 3D poses and enforce the 3D poses estimated from multi-views to be consistent. Therefore, our method relaxes the constraints in practice, only multi-view videos are required for training, and is thus convenient for in-the-wild settings. At inference, RLN merely requires single-view videos. The proposed method outperforms previous works on two challenging datasets, Human3.6M and MPI-INF-3DHP. Codes and pretrained models will be publicly available.
Multi-view 3D Reconstruction with Transformer
Mar 24, 2021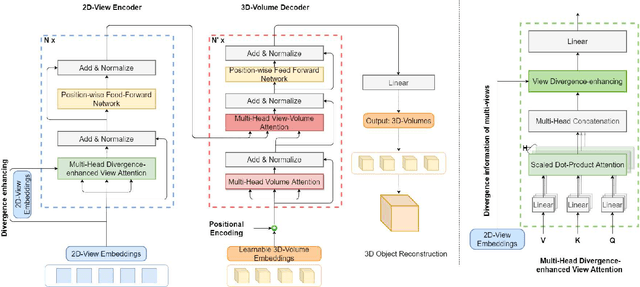



Deep CNN-based methods have so far achieved the state of the art results in multi-view 3D object reconstruction. Despite the considerable progress, the two core modules of these methods - multi-view feature extraction and fusion, are usually investigated separately, and the object relations in different views are rarely explored. In this paper, inspired by the recent great success in self-attention-based Transformer models, we reformulate the multi-view 3D reconstruction as a sequence-to-sequence prediction problem and propose a new framework named 3D Volume Transformer (VolT) for such a task. Unlike previous CNN-based methods using a separate design, we unify the feature extraction and view fusion in a single Transformer network. A natural advantage of our design lies in the exploration of view-to-view relationships using self-attention among multiple unordered inputs. On ShapeNet - a large-scale 3D reconstruction benchmark dataset, our method achieves a new state-of-the-art accuracy in multi-view reconstruction with fewer parameters ($70\%$ less) than other CNN-based methods. Experimental results also suggest the strong scaling capability of our method. Our code will be made publicly available.
Adversarial Attacks on Camera-LiDAR Models for 3D Car Detection
Mar 17, 2021
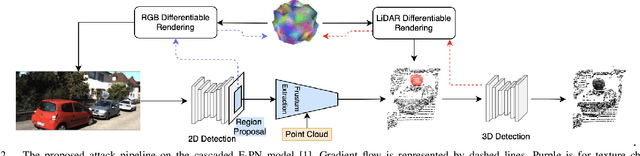
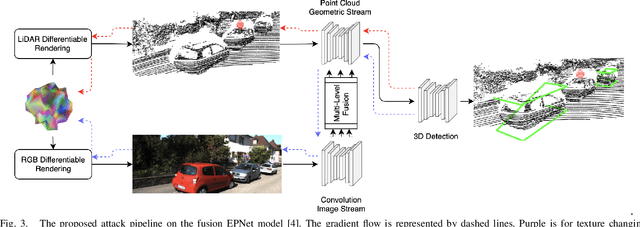
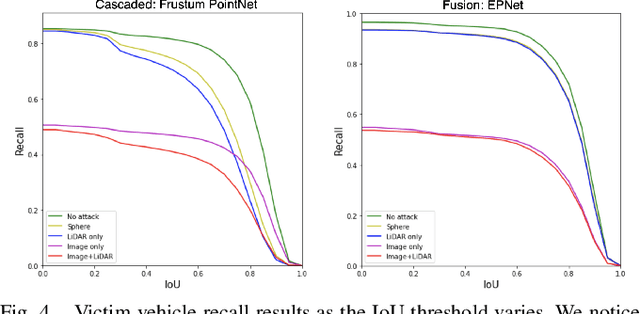
Most autonomous vehicles (AVs) rely on LiDAR and RGB camera sensors for perception. Using these point cloud and image data, perception models based on deep neural nets (DNNs) have achieved state-of-the-art performance in 3D detection. The vulnerability of DNNs to adversarial attacks have been heavily investigated in the RGB image domain and more recently in the point cloud domain, but rarely in both domains simultaneously. Multi-modal perception systems used in AVs can be divided into two broad types: cascaded models which use each modality independently, and fusion models which learn from different modalities simultaneously. We propose a universal and physically realizable adversarial attack for each type, and study and contrast their respective vulnerabilities to attacks. We place a single adversarial object with specific shape and texture on top of a car with the objective of making this car evade detection. Evaluating on the popular KITTI benchmark, our adversarial object made the host vehicle escape detection by each model type nearly 50% of the time. The dense RGB input contributed more to the success of the adversarial attacks on both cascaded and fusion models. We found that the fusion model was relatively more robust to adversarial attacks than the cascaded model.
Towards Universal Physical Attacks On Cascaded Camera-Lidar 3D Object Detection Models
Jan 31, 2021
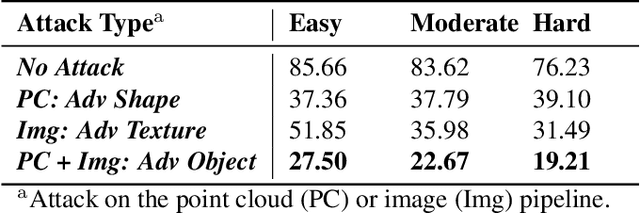
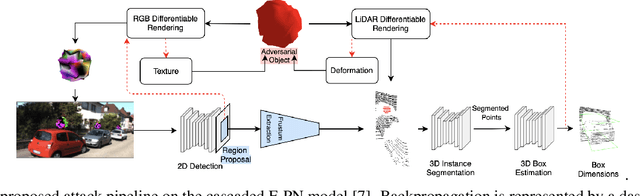
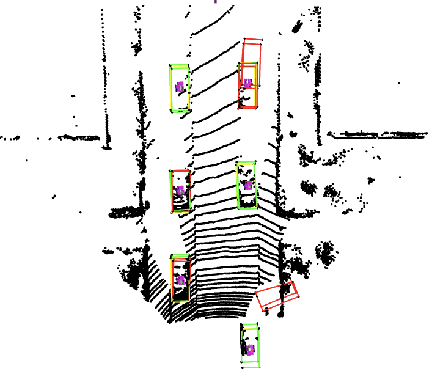
We propose a universal and physically realizable adversarial attack on a cascaded multi-modal deep learning network (DNN), in the context of self-driving cars. DNNs have achieved high performance in 3D object detection, but they are known to be vulnerable to adversarial attacks. These attacks have been heavily investigated in the RGB image domain and more recently in the point cloud domain, but rarely in both domains simultaneously - a gap to be filled in this paper. We use a single 3D mesh and differentiable rendering to explore how perturbing the mesh's geometry and texture can reduce the robustness of DNNs to adversarial attacks. We attack a prominent cascaded multi-modal DNN, the Frustum-Pointnet model. Using the popular KITTI benchmark, we showed that the proposed universal multi-modal attack was successful in reducing the model's ability to detect a car by nearly 73%. This work can aid in the understanding of what the cascaded RGB-point cloud DNN learns and its vulnerability to adversarial attacks.
Perception Improvement for Free: Exploring Imperceptible Black-box Adversarial Attacks on Image Classification
Oct 30, 2020
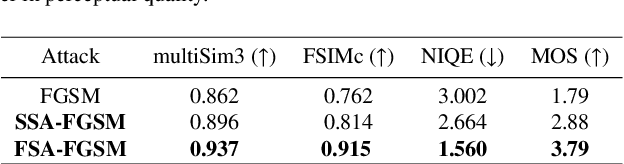


Deep neural networks are vulnerable to adversarial attacks. White-box adversarial attacks can fool neural networks with small adversarial perturbations, especially for large size images. However, keeping successful adversarial perturbations imperceptible is especially challenging for transfer-based black-box adversarial attacks. Often such adversarial examples can be easily spotted due to their unpleasantly poor visual qualities, which compromises the threat of adversarial attacks in practice. In this study, to improve the image quality of black-box adversarial examples perceptually, we propose structure-aware adversarial attacks by generating adversarial images based on psychological perceptual models. Specifically, we allow higher perturbations on perceptually insignificant regions, while assigning lower or no perturbation on visually sensitive regions. In addition to the proposed spatial-constrained adversarial perturbations, we also propose a novel structure-aware frequency adversarial attack method in the discrete cosine transform (DCT) domain. Since the proposed attacks are independent of the gradient estimation, they can be directly incorporated with existing gradient-based attacks. Experimental results show that, with the comparable attack success rate (ASR), the proposed methods can produce adversarial examples with considerably improved visual quality for free. With the comparable perceptual quality, the proposed approaches achieve higher attack success rates: particularly for the frequency structure-aware attacks, the average ASR improves more than 10% over the baseline attacks.
Perception Matters: Exploring Imperceptible and Transferable Anti-forensics for GAN-generated Fake Face Imagery Detection
Oct 29, 2020
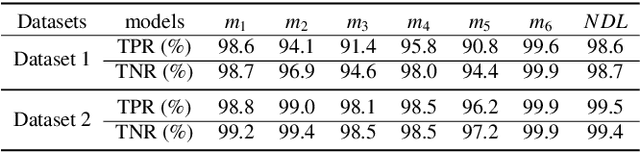
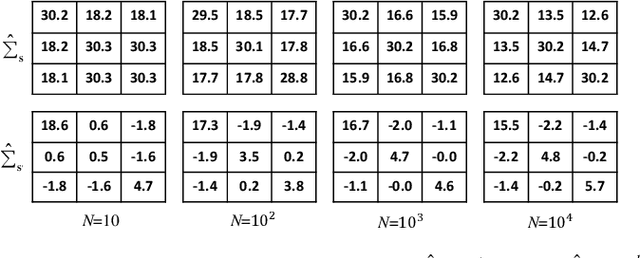
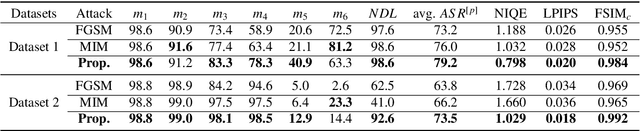
Recently, generative adversarial networks (GANs) can generate photo-realistic fake facial images which are perceptually indistinguishable from real face photos, promoting research on fake face detection. Though fake face forensics can achieve high detection accuracy, their anti-forensic counterparts are less investigated. Here we explore more \textit{imperceptible} and \textit{transferable} anti-forensics for fake face imagery detection based on adversarial attacks. Since facial and background regions are often smooth, even small perturbation could cause noticeable perceptual impairment in fake face images. Therefore it makes existing adversarial attacks ineffective as an anti-forensic method. Our perturbation analysis reveals the intuitive reason of the perceptual degradation issue when directly applying existing attacks. We then propose a novel adversarial attack method, better suitable for image anti-forensics, in the transformed color domain by considering visual perception. Simple yet effective, the proposed method can fool both deep learning and non-deep learning based forensic detectors, achieving higher attack success rate and significantly improved visual quality. Specially, when adversaries consider imperceptibility as a constraint, the proposed anti-forensic method can improve the average attack success rate by around 30\% on fake face images over two baseline attacks. \textit{More imperceptible} and \textit{more transferable}, the proposed method raises new security concerns to fake face imagery detection. We have released our code for public use, and hopefully the proposed method can be further explored in related forensic applications as an anti-forensic benchmark.