 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriPose: A Weakly-Supervised 3D Human Pose Estimation via Triangulation from Video
Paper and Code
May 14, 2021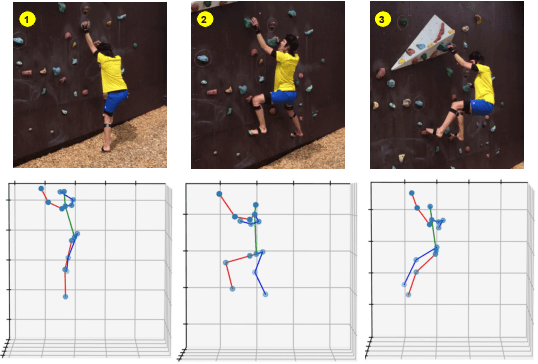
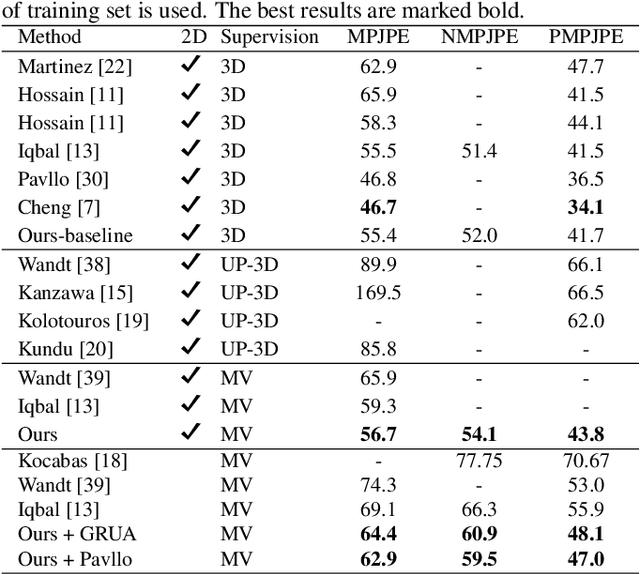
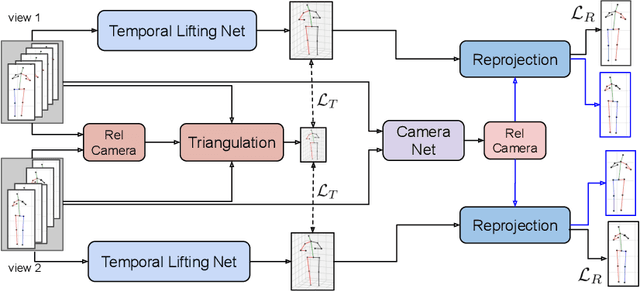
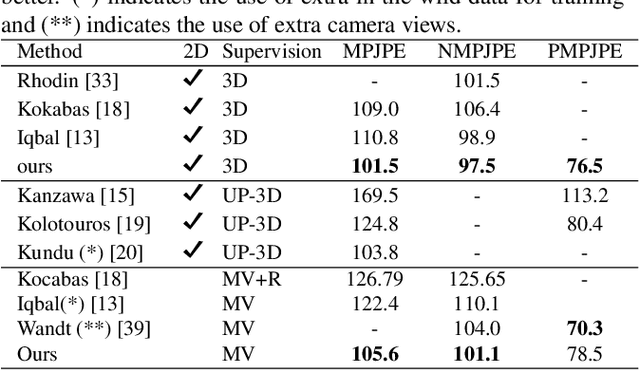
Estimating 3D human poses from video is a challenging problem. The lack of 3D human pose annotations is a major obstacle for supervised training and for generalization to unseen datasets. In this work, we address this problem by proposing a weakly-supervised training scheme that does not require 3D annotations or calibrated cameras. The proposed method relies on temporal information and triangulation. Using 2D poses from multiple views as the input, we first estimate the relative camera orientations and then generate 3D poses via triangulation. The triangulation is only applied to the views with high 2D human joint confidence. The generated 3D poses are then used to train a recurrent lifting network (RLN) that estimates 3D poses from 2D poses. We further apply a multi-view re-projection loss to the estimated 3D poses and enforce the 3D poses estimated from multi-views to be consistent. Therefore, our method relaxes the constraints in practice, only multi-view videos are required for training, and is thus convenient for in-the-wild settings. At inference, RLN merely requires single-view videos. The proposed method outperforms previous works on two challenging datasets, Human3.6M and MPI-INF-3DHP. Codes and pretrained models will be publicly available.