 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPPO: Contrastive Perception for Vision Language Policy Optimization
Jan 01, 2026We introduce CPPO, a Contrastive Perception Policy Optimization method for finetuning vision-language models (VLMs). While reinforcement learning (RL) has advanced reasoning in language models, extending it to multimodal reasoning requires improving both the perception and reasoning aspects. Prior works tackle this challenge mainly with explicit perception rewards, but disentangling perception tokens from reasoning tokens is difficult, requiring extra LLMs, ground-truth data, forced separation of perception from reasoning by policy model, or applying rewards indiscriminately to all output tokens. CPPO addresses this problem by detecting perception tokens via entropy shifts in the model outputs under perturbed input images. CPPO then extends the RL objective function with a Contrastive Perception Loss (CPL) that enforces consistency under information-preserving perturbations and sensitivity under information-removing ones. Experiments show that CPPO surpasses previous perception-rewarding methods, while avoiding extra models, making training more efficient and scalable.
CASP: Compression of Large Multimodal Models Based on Attention Sparsity
Mar 07, 2025



In this work, we propose an extreme compression technique for Large Multimodal Models (LMMs). While previous studies have explored quantization as an efficient post-training compression method for Large Language Models (LLMs), low-bit compression for multimodal models remains under-explored. The redundant nature of inputs in multimodal models results in a highly sparse attention matrix. We theoretically and experimentally demonstrate that the attention matrix's sparsity bounds the compression error of the Query and Key weight matrices. Based on this, we introduce CASP, a model compression technique for LMMs. Our approach performs a data-aware low-rank decomposition on the Query and Key weight matrix, followed by quantization across all layers based on an optimal bit allocation process. CASP is compatible with any quantization technique and enhances state-of-the-art 2-bit quantization methods (AQLM and QuIP#) by an average of 21% on image- and video-language benchmarks.
ESCAPE: Energy-based Selective Adaptive Correction for Out-of-distribution 3D Human Pose Estimation
Jul 19, 2024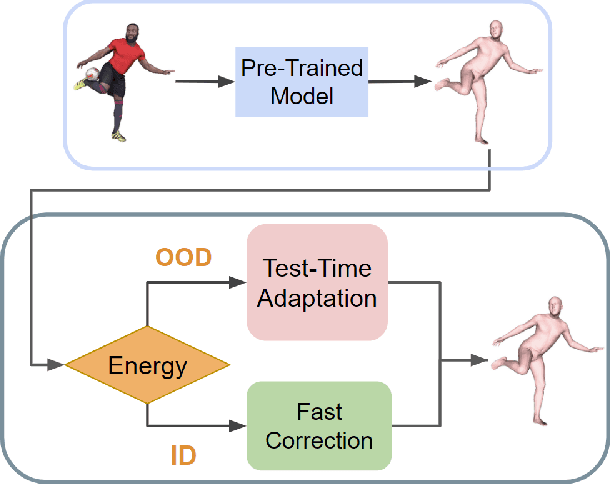
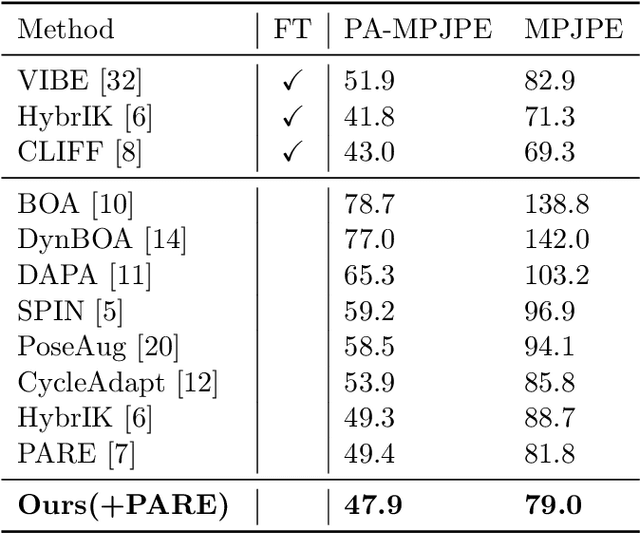
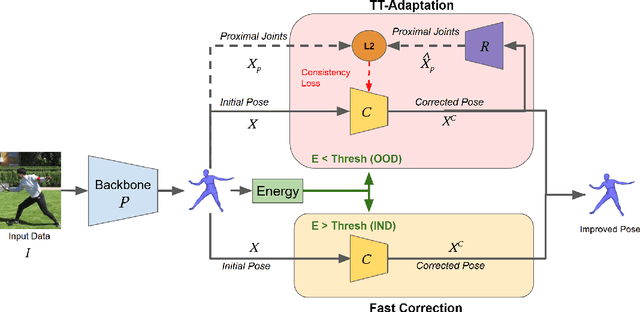
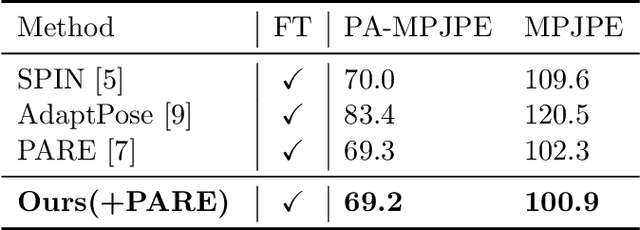
Despite recent advances in human pose estimation (HPE), poor generalization to out-of-distribution (OOD) data remains a difficult problem. While previous works have proposed Test-Time Adaptation (TTA) to bridge the train-test domain gap by refining network parameters at inference, the absence of ground-truth annotations makes it highly challenging and existing methods typically increase inference times by one or more orders of magnitude. We observe that 1) not every test time sample is OOD, and 2) HPE errors are significantly larger on distal keypoints (wrist, ankle). To this end, we propose ESCAPE: a lightweight correction and selective adaptation framework which applies a fast, forward-pass correction on most data while reserving costly TTA for OOD data. The free energy function is introduced to separate OOD samples from incoming data and a correction network is trained to estimate the errors of pretrained backbone HPE predictions on the distal keypoints. For OOD samples, we propose a novel self-consistency adaptation loss to update the correction network by leveraging the constraining relationship between distal keypoints and proximal keypoints (shoulders, hips), via a second ``reverse" network. ESCAPE improves the distal MPJPE of five popular HPE models by up to 7% on unseen data, achieves state-of-the-art results on two popular HPE benchmarks, and is significantly faster than existing adaptation methods.
GOLD: Generalized Knowledge Distillation via Out-of-Distribution-Guided Language Data Generation
Mar 28, 2024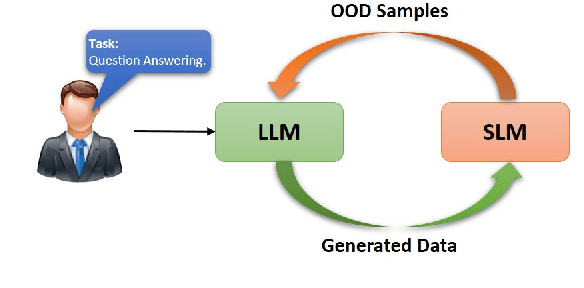

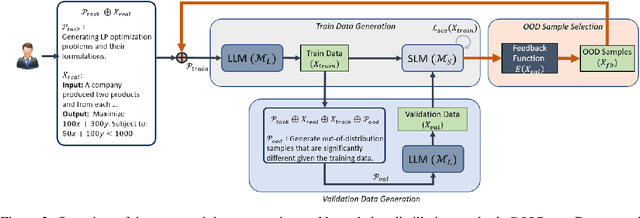
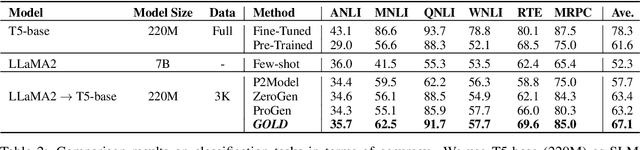
Knowledge distillation from LLMs is essential for the efficient deployment of language models. Prior works have proposed data generation using LLMs for preparing distilled models. We argue that generating data with LLMs is prone to sampling mainly from the center of original content distribution. This limitation hinders the distilled model from learning the true underlying data distribution and to forget the tails of the distributions (samples with lower probability). To this end, we propose GOLD, a task-agnostic data generation and knowledge distillation framework, which employs an iterative out-of-distribution-guided feedback mechanism for the LLM. As a result, the generated data improves the generalizability of distilled models. An energy-based OOD evaluation approach is also introduced to deal with noisy generated data. Our extensive experiments on 10 different classification and sequence-to-sequence tasks in NLP show that GOLD respectively outperforms prior arts and the LLM with an average improvement of 5% and 14%. We will also show that the proposed method is applicable to less explored and novel tasks. The code is available.
PoseGen: Learning to Generate 3D Human Pose Dataset with NeRF
Dec 22, 2023This paper proposes an end-to-end framework for generating 3D human pose datasets using Neural Radiance Fields (NeRF). Public datasets generally have limited diversity in terms of human poses and camera viewpoints, largely due to the resource-intensive nature of collecting 3D human pose data. As a result, pose estimators trained on public datasets significantly underperform when applied to unseen out-of-distribution samples. Previous works proposed augmenting public datasets by generating 2D-3D pose pairs or rendering a large amount of random data. Such approaches either overlook image rendering or result in suboptimal datasets for pre-trained models. Here we propose PoseGen, which learns to generate a dataset (human 3D poses and images) with a feedback loss from a given pre-trained pose estimator. In contrast to prior art, our generated data is optimized to improve the robustness of the pre-trained model. The objective of PoseGen is to learn a distribution of data that maximizes the prediction error of a given pre-trained model. As the learned data distribution contains OOD samples of the pre-trained model, sampling data from such a distribution for further fine-tuning a pre-trained model improves the generalizability of the model. This is the first work that proposes NeRFs for 3D human data generation. NeRFs are data-driven and do not require 3D scans of humans. Therefore, using NeRF for data generation is a new direction for convenient user-specific data generation. Our extensive experiments show that the proposed PoseGen improves two baseline models (SPIN and HybrIK) on four datasets with an average 6% relative improvement.
ETran: Energy-Based Transferability Estimation
Aug 03, 2023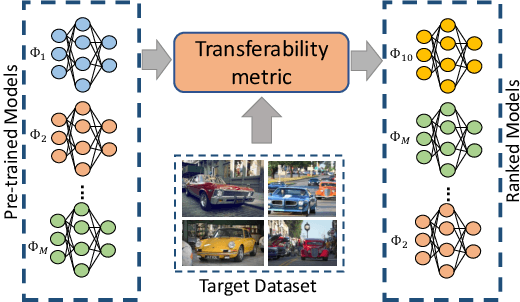
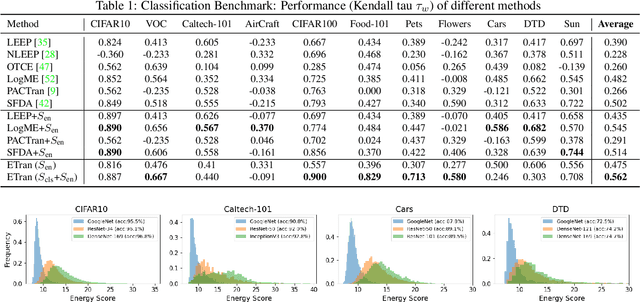
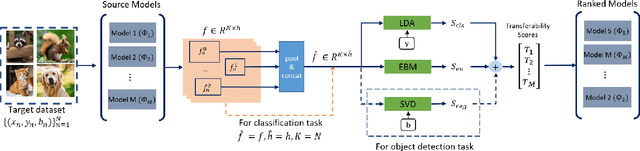
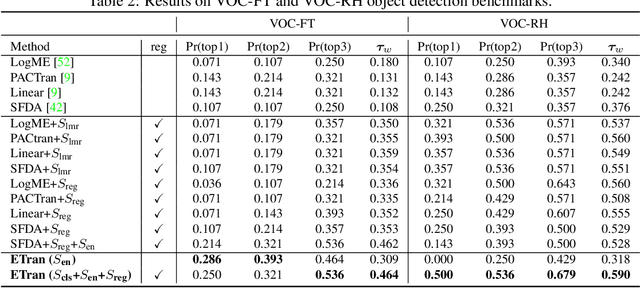
This paper addresses the problem of ranking pre-trained models for object detection and image classification. Selecting the best pre-trained model by fine-tuning is an expensive and time-consuming task. Previous works have proposed transferability estimation based on features extracted by the pre-trained models. We argue that quantifying whether the target dataset is in-distribution (IND) or out-of-distribution (OOD) for the pre-trained model is an important factor in the transferability estimation. To this end, we propose ETran, an energy-based transferability assessment metric, which includes three scores: 1) energy score, 2) classification score, and 3) regression score. We use energy-based models to determine whether the target dataset is OOD or IND for the pre-trained model. In contrast to the prior works, ETran is applicable to a wide range of tasks including classification, regression, and object detection (classification+regression). This is the first work that proposes transferability estimation for object detection task. Our extensive experiments on four benchmarks and two tasks show that ETran outperforms previous works on object detection and classification benchmarks by an average of 21% and 12%, respectively, and achieves SOTA in transferability assessment.
AdaptPose: Cross-Dataset Adaptation for 3D Human Pose Estimation by Learnable Motion Generation
Dec 22, 2021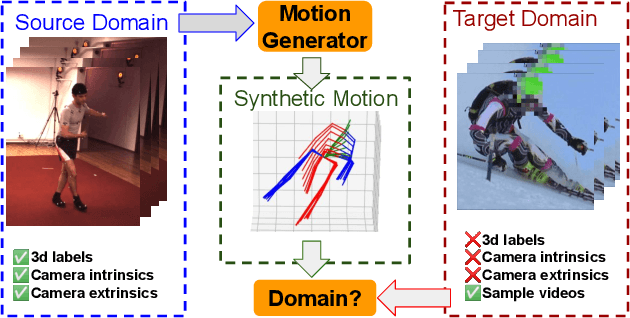
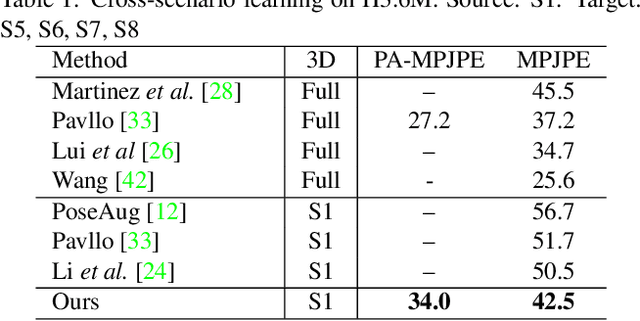
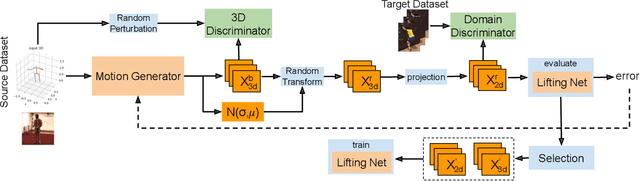
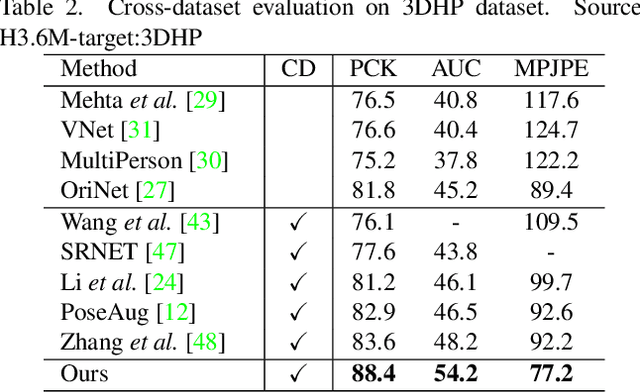
This paper addresses the problem of cross-dataset generalization of 3D human pose estimation models. Testing a pre-trained 3D pose estimator on a new dataset results in a major performance drop. Previous methods have mainly addressed this problem by improving the diversity of the training data. We argue that diversity alone is not sufficient and that the characteristics of the training data need to be adapted to those of the new dataset such as camera viewpoint, position, human actions, and body size. To this end, we propose AdaptPose, an end-to-end framework that generates synthetic 3D human motions from a source dataset and uses them to fine-tune a 3D pose estimator. AdaptPose follows an adversarial training scheme. From a source 3D pose the generator generates a sequence of 3D poses and a camera orientation that is used to project the generated poses to a novel view. Without any 3D labels or camera information AdaptPose successfully learns to create synthetic 3D poses from the target dataset while only being trained on 2D poses. In experiments on the Human3.6M, MPI-INF-3DHP, 3DPW, and Ski-Pose datasets our method outperforms previous work in cross-dataset evaluations by 14% and previous semi-supervised learning methods that use partial 3D annotations by 16%.
TriPose: A Weakly-Supervised 3D Human Pose Estimation via Triangulation from Video
May 14, 2021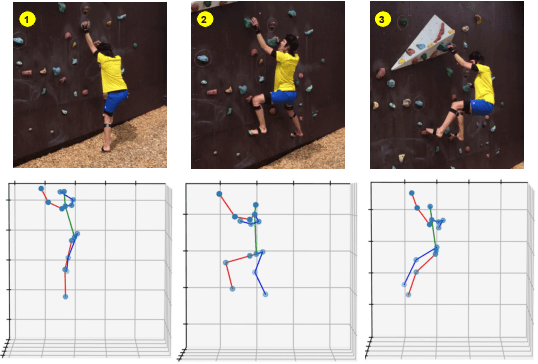
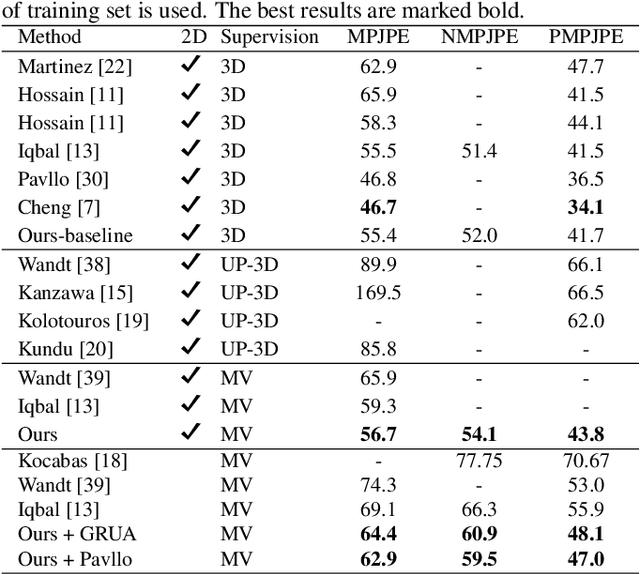
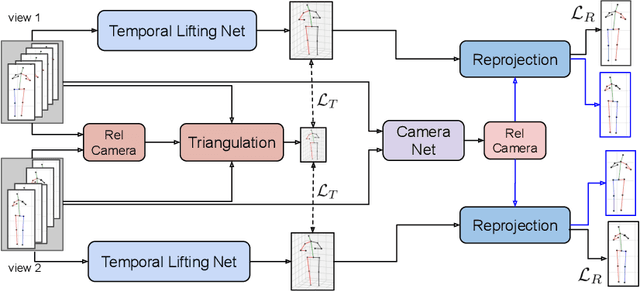
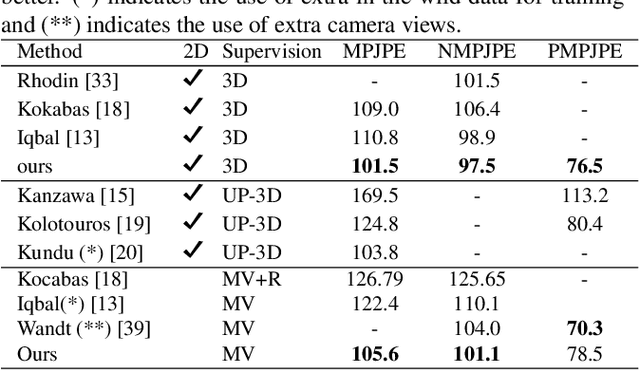
Estimating 3D human poses from video is a challenging problem. The lack of 3D human pose annotations is a major obstacle for supervised training and for generalization to unseen datasets. In this work, we address this problem by proposing a weakly-supervised training scheme that does not require 3D annotations or calibrated cameras. The proposed method relies on temporal information and triangulation. Using 2D poses from multiple views as the input, we first estimate the relative camera orientations and then generate 3D poses via triangulation. The triangulation is only applied to the views with high 2D human joint confidence. The generated 3D poses are then used to train a recurrent lifting network (RLN) that estimates 3D poses from 2D poses. We further apply a multi-view re-projection loss to the estimated 3D poses and enforce the 3D poses estimated from multi-views to be consistent. Therefore, our method relaxes the constraints in practice, only multi-view videos are required for training, and is thus convenient for in-the-wild settings. At inference, RLN merely requires single-view videos. The proposed method outperforms previous works on two challenging datasets, Human3.6M and MPI-INF-3DHP. Codes and pretrained models will be publicly available.