 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Physical Attacks On Cascaded Camera-Lidar 3D Object Detection Models
Paper and Code
Jan 31, 2021
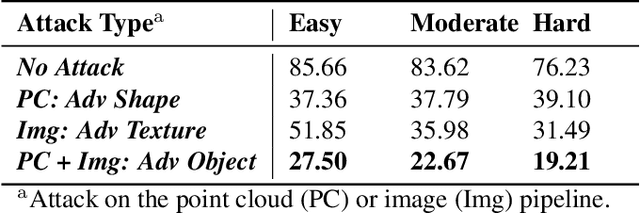
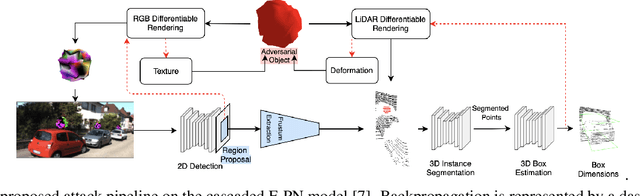
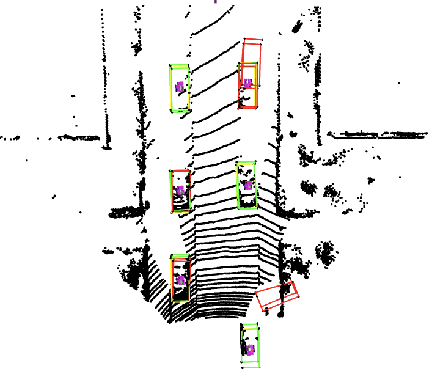
We propose a universal and physically realizable adversarial attack on a cascaded multi-modal deep learning network (DNN), in the context of self-driving cars. DNNs have achieved high performance in 3D object detection, but they are known to be vulnerable to adversarial attacks. These attacks have been heavily investigated in the RGB image domain and more recently in the point cloud domain, but rarely in both domains simultaneously - a gap to be filled in this paper. We use a single 3D mesh and differentiable rendering to explore how perturbing the mesh's geometry and texture can reduce the robustness of DNNs to adversarial attacks. We attack a prominent cascaded multi-modal DNN, the Frustum-Pointnet model. Using the popular KITTI benchmark, we showed that the proposed universal multi-modal attack was successful in reducing the model's ability to detect a car by nearly 73%. This work can aid in the understanding of what the cascaded RGB-point cloud DNN learns and its vulnerability to adversarial attacks.