 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Streaming 3D Object Detection
Sep 12, 2022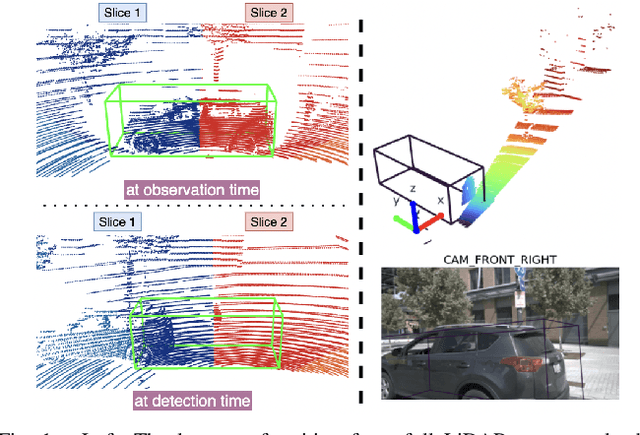
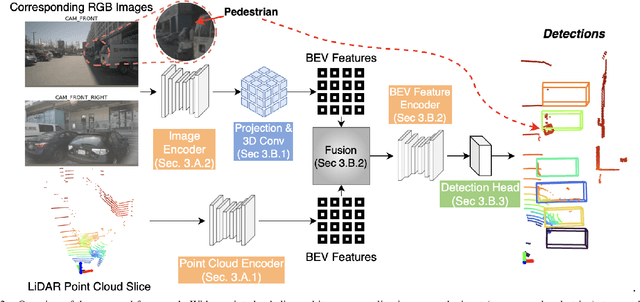
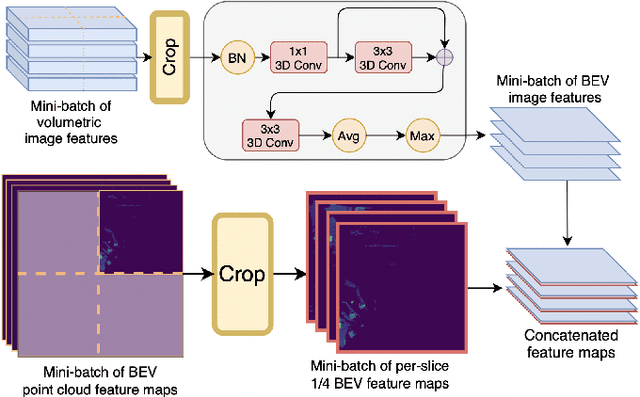

Modern autonomous vehicles rely heavily on mechanical LiDARs for perception. Current perception methods generally require 360{\deg} point clouds, collected sequentially as the LiDAR scans the azimuth and acquires consecutive wedge-shaped slices. The acquisition latency of a full scan (~ 100ms) may lead to outdated perception which is detrimental to safe operation. Recent streaming perception works proposed directly processing LiDAR slices and compensating for the narrow field of view (FOV) of a slice by reusing features from preceding slices. These works, however, are all based on a single modality and require past information which may be outdated. Meanwhile, images from high-frequency cameras can support streaming models as they provide a larger FoV compared to a LiDAR slice. However, this difference in FoV complicates sensor fusion. To address this research gap, we propose an innovative camera-LiDAR streaming 3D object detection framework that uses camera images instead of past LiDAR slices to provide an up-to-date, dense, and wide context for streaming perception. The proposed method outperforms prior streaming models on the challenging NuScenes benchmark. It also outperforms powerful full-scan detectors while being much faster. Our method is shown to be robust to missing camera images, narrow LiDAR slices, and small camera-LiDAR miscalibration.
Adversarial Attacks on Camera-LiDAR Models for 3D Car Detection
Mar 17, 2021
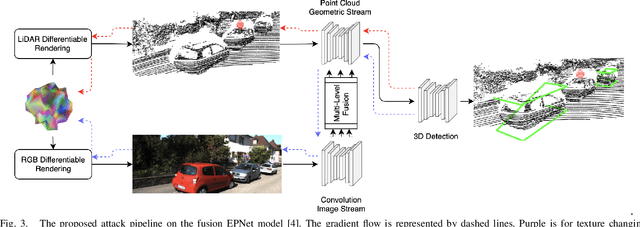
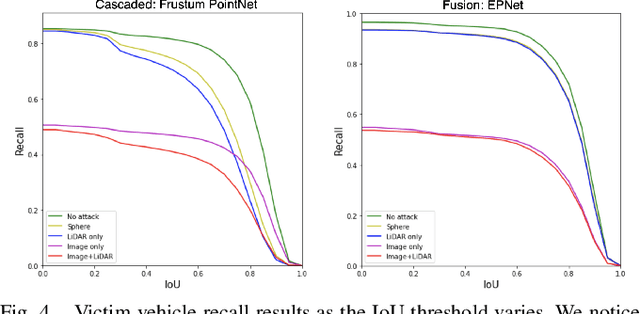
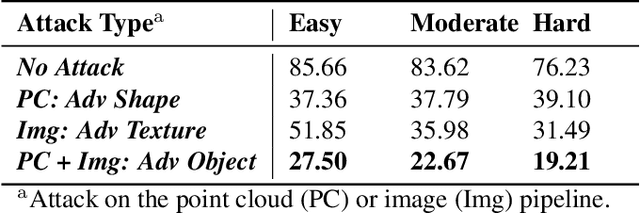
Most autonomous vehicles (AVs) rely on LiDAR and RGB camera sensors for perception. Using these point cloud and image data, perception models based on deep neural nets (DNNs) have achieved state-of-the-art performance in 3D detection. The vulnerability of DNNs to adversarial attacks have been heavily investigated in the RGB image domain and more recently in the point cloud domain, but rarely in both domains simultaneously. Multi-modal perception systems used in AVs can be divided into two broad types: cascaded models which use each modality independently, and fusion models which learn from different modalities simultaneously. We propose a universal and physically realizable adversarial attack for each type, and study and contrast their respective vulnerabilities to attacks. We place a single adversarial object with specific shape and texture on top of a car with the objective of making this car evade detection. Evaluating on the popular KITTI benchmark, our adversarial object made the host vehicle escape detection by each model type nearly 50% of the time. The dense RGB input contributed more to the success of the adversarial attacks on both cascaded and fusion models. We found that the fusion model was relatively more robust to adversarial attacks than the cascaded model.
Towards Universal Physical Attacks On Cascaded Camera-Lidar 3D Object Detection Models
Jan 31, 2021
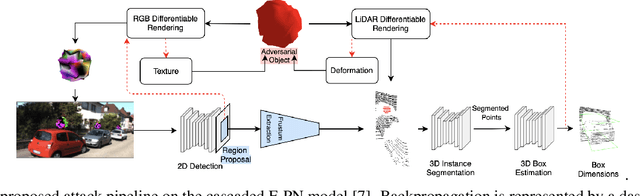
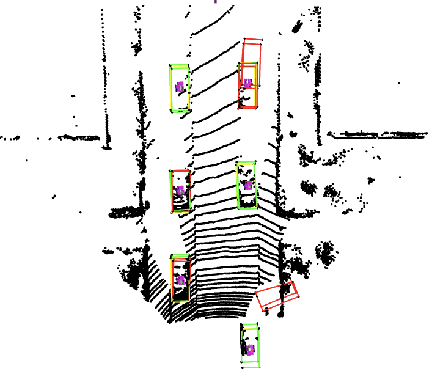
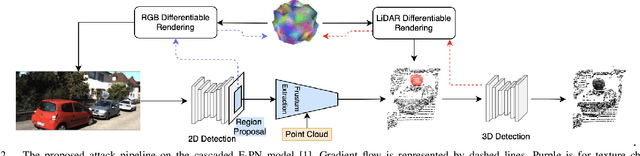
We propose a universal and physically realizable adversarial attack on a cascaded multi-modal deep learning network (DNN), in the context of self-driving cars. DNNs have achieved high performance in 3D object detection, but they are known to be vulnerable to adversarial attacks. These attacks have been heavily investigated in the RGB image domain and more recently in the point cloud domain, but rarely in both domains simultaneously - a gap to be filled in this paper. We use a single 3D mesh and differentiable rendering to explore how perturbing the mesh's geometry and texture can reduce the robustness of DNNs to adversarial attacks. We attack a prominent cascaded multi-modal DNN, the Frustum-Pointnet model. Using the popular KITTI benchmark, we showed that the proposed universal multi-modal attack was successful in reducing the model's ability to detect a car by nearly 73%. This work can aid in the understanding of what the cascaded RGB-point cloud DNN learns and its vulnerability to adversarial attacks.