 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceLinkGen: Rethinking Identity Leakage in Privacy-Preserving Face Recognition with Identity Extraction
Feb 02, 2026Transformation-based privacy-preserving face recognition (PPFR) aims to verify identities while hiding facial data from attackers and malicious service providers. Existing evaluations mostly treat privacy as resistance to pixel-level reconstruction, measured by PSNR and SSIM. We show that this reconstruction-centric view fails. We present FaceLinkGen, an identity extraction attack that performs linkage/matching and face regeneration directly from protected templates without recovering original pixels. On three recent PPFR systems, FaceLinkGen reaches over 98.5\% matching accuracy and above 96\% regeneration success, and still exceeds 92\% matching and 94\% regeneration in a near zero knowledge setting. These results expose a structural gap between pixel distortion metrics, which are widely used in PPFR evaluation, and real privacy. We show that visual obfuscation leaves identity information broadly exposed to both external intruders and untrusted service providers.
Aesthetic Alignment Risks Assimilation: How Image Generation and Reward Models Reinforce Beauty Bias and Ideological "Censorship"
Dec 09, 2025Over-aligning image generation models to a generalized aesthetic preference conflicts with user intent, particularly when ``anti-aesthetic" outputs are requested for artistic or critical purposes. This adherence prioritizes developer-centered values, compromising user autonomy and aesthetic pluralism. We test this bias by constructing a wide-spectrum aesthetics dataset and evaluating state-of-the-art generation and reward models. We find that aesthetic-aligned generation models frequently default to conventionally beautiful outputs, failing to respect instructions for low-quality or negative imagery. Crucially, reward models penalize anti-aesthetic images even when they perfectly match the explicit user prompt. We confirm this systemic bias through image-to-image editing and evaluation against real abstract artworks.
JVLGS: Joint Vision-Language Gas Leak Segmentation
Aug 27, 2025Gas leaks pose serious threats to human health and contribute significantly to atmospheric pollution, drawing increasing public concern. However, the lack of effective detection methods hampers timely and accurate identification of gas leaks. While some vision-based techniques leverage infrared videos for leak detection, the blurry and non-rigid nature of gas clouds often limits their effectiveness. To address these challenges, we propose a novel framework called Joint Vision-Language Gas leak Segmentation (JVLGS), which integrates the complementary strengths of visual and textual modalities to enhance gas leak representation and segmentation. Recognizing that gas leaks are sporadic and many video frames may contain no leak at all, our method incorporates a post-processing step to reduce false positives caused by noise and non-target objects, an issue that affects many existing approaches. Extensive experiments conducted across diverse scenarios show that JVLGS significantly outperforms state-of-the-art gas leak segmentation methods. We evaluate our model under both supervised and few-shot learning settings, and it consistently achieves strong performance in both, whereas competing methods tend to perform well in only one setting or poorly in both. Code available at: https://github.com/GeekEagle/JVLGS
Fine-grained spatial-temporal perception for gas leak segmentation
May 01, 2025Gas leaks pose significant risks to human health and the environment. Despite long-standing concerns, there are limited methods that can efficiently and accurately detect and segment leaks due to their concealed appearance and random shapes. In this paper, we propose a Fine-grained Spatial-Temporal Perception (FGSTP) algorithm for gas leak segmentation. FGSTP captures critical motion clues across frames and integrates them with refined object features in an end-to-end network. Specifically, we first construct a correlation volume to capture motion information between consecutive frames. Then, the fine-grained perception progressively refines the object-level features using previous outputs. Finally, a decoder is employed to optimize boundary segmentation. Because there is no highly precise labeled dataset for gas leak segmentation, we manually label a gas leak video dataset, GasVid. Experimental results on GasVid demonstrate that our model excels in segmenting non-rigid objects such as gas leaks, generating the most accurate mask compared to other state-of-the-art (SOTA) models.
StyleMorpheus: A Style-Based 3D-Aware Morphable Face Model
Mar 14, 2025



For 3D face modeling, the recently developed 3D-aware neural rendering methods are able to render photorealistic face images with arbitrary viewing directions. The training of the parametric controllable 3D-aware face models, however, still relies on a large-scale dataset that is lab-collected. To address this issue, this paper introduces "StyleMorpheus", the first style-based neural 3D Morphable Face Model (3DMM) that is trained on in-the-wild images. It inherits 3DMM's disentangled controllability (over face identity, expression, and appearance) but without the need for accurately reconstructed explicit 3D shapes. StyleMorpheus employs an auto-encoder structure. The encoder aims at learning a representative disentangled parametric code space and the decoder improves the disentanglement using shape and appearance-related style codes in the different sub-modules of the network. Furthermore, we fine-tune the decoder through style-based generative adversarial learning to achieve photorealistic 3D rendering quality. The proposed style-based design enables StyleMorpheus to achieve state-of-the-art 3D-aware face reconstruction results, while also allowing disentangled control of the reconstructed face. Our model achieves real-time rendering speed, allowing its use in virtual reality applications. We also demonstrate the capability of the proposed style-based design in face editing applications such as style mixing and color editing. Project homepage: https://github.com/ubc-3d-vision-lab/StyleMorpheus.
LangGas: Introducing Language in Selective Zero-Shot Background Subtraction for Semi-Transparent Gas Leak Detection with a New Dataset
Mar 06, 2025



Gas leakage poses a significant hazard that requires prevention. Traditionally, human inspection has been used for detection, a slow and labour-intensive process. Recent research has applied machine learning techniques to this problem, yet there remains a shortage of high-quality, publicly available datasets. This paper introduces a synthetic dataset featuring diverse backgrounds, interfering foreground objects, diverse leak locations, and precise segmentation ground truth. We propose a zero-shot method that combines background subtraction, zero-shot object detection, filtering, and segmentation to leverage this dataset. Experimental results indicate that our approach significantly outperforms baseline methods based solely on background subtraction and zero-shot object detection with segmentation, reaching an IoU of 69\% overall. We also present an analysis of various prompt configurations and threshold settings to provide deeper insights into the performance of our method. The code and dataset will be released after publication.
Gaussian Deja-vu: Creating Controllable 3D Gaussian Head-Avatars with Enhanced Generalization and Personalization Abilities
Sep 26, 2024
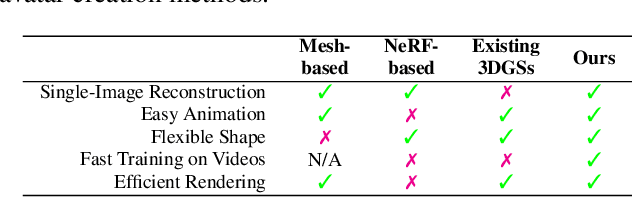


Recent advancements in 3D Gaussian Splatting (3DGS) have unlocked significant potential for modeling 3D head avatars, providing greater flexibility than mesh-based methods and more efficient rendering compared to NeRF-based approaches. Despite these advancements, the creation of controllable 3DGS-based head avatars remains time-intensive, often requiring tens of minutes to hours. To expedite this process, we here introduce the ``Gaussian D\'ej\`a-vu" framework, which first obtains a generalized model of the head avatar and then personalizes the result. The generalized model is trained on large 2D (synthetic and real) image datasets. This model provides a well-initialized 3D Gaussian head that is further refined using a monocular video to achieve the personalized head avatar. For personalizing, we propose learnable expression-aware rectification blendmaps to correct the initial 3D Gaussians, ensuring rapid convergence without the reliance on neural networks. Experiments demonstrate that the proposed method meets its objectives. It outperforms state-of-the-art 3D Gaussian head avatars in terms of photorealistic quality as well as reduces training time consumption to at least a quarter of the existing methods, producing the avatar in minutes.
Real-World Image Super Resolution via Unsupervised Bi-directional Cycle Domain Transfer Learning based Generative Adversarial Network
Nov 19, 2022



Deep Convolutional Neural Networks (DCNNs) have exhibited impressive performance on image super-resolution tasks. However, these deep learning-based super-resolution methods perform poorly in real-world super-resolution tasks, where the paired high-resolution and low-resolution images are unavailable and the low-resolution images are degraded by complicated and unknown kernels. To break these limitations, we propose the Unsupervised Bi-directional Cycle Domain Transfer Learning-based Generative Adversarial Network (UBCDTL-GAN), which consists of an Unsupervised Bi-directional Cycle Domain Transfer Network (UBCDTN) and the Semantic Encoder guided Super Resolution Network (SESRN). First, the UBCDTN is able to produce an approximated real-like LR image through transferring the LR image from an artificially degraded domain to the real-world LR image domain. Second, the SESRN has the ability to super-resolve the approximated real-like LR image to a photo-realistic HR image. Extensive experiments on unpaired real-world image benchmark datasets demonstrate that the proposed method achieves superior performance compared to state-of-the-art methods.
Semantic Encoder Guided Generative Adversarial Face Ultra-Resolution Network
Nov 18, 2022



Face super-resolution is a domain-specific image super-resolution, which aims to generate High-Resolution (HR) face images from their Low-Resolution (LR) counterparts. In this paper, we propose a novel face super-resolution method, namely Semantic Encoder guided Generative Adversarial Face Ultra-Resolution Network (SEGA-FURN) to ultra-resolve an unaligned tiny LR face image to its HR counterpart with multiple ultra-upscaling factors (e.g., 4x and 8x). The proposed network is composed of a novel semantic encoder that has the ability to capture the embedded semantics to guide adversarial learning and a novel generator that uses a hierarchical architecture named Residual in Internal Dense Block (RIDB). Moreover, we propose a joint discriminator which discriminates both image data and embedded semantics. The joint discriminator learns the joint probability distribution of the image space and latent space. We also use a Relativistic average Least Squares loss (RaLS) as the adversarial loss to alleviate the gradient vanishing problem and enhance the stability of the training procedure. Extensive experiments on large face datasets have proved that the proposed method can achieve superior super-resolution results and significantly outperform other state-of-the-art methods in both qualitative and quantitative comparisons.
Spatiotemporal Multi-scale Bilateral Motion Network for Gait Recognition
Sep 26, 2022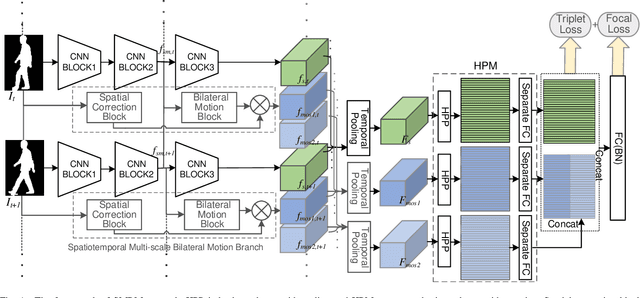


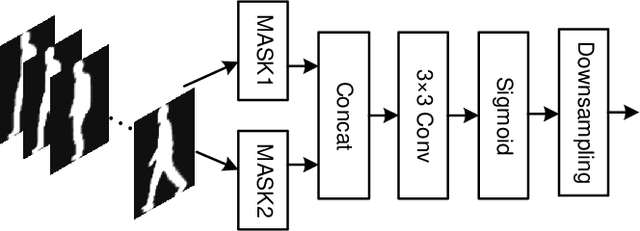
The critical goal of gait recognition is to acquire the inter-frame walking habit representation from the gait sequences. The relations between frames, however, have not received adequate attention in comparison to the intra-frame features. In this paper, motivated by optical flow, the bilateral motion-oriented features are proposed, which can allow the classic convolutional structure to have the capability to directly portray gait movement patterns at the feature level. Based on such features, we develop a set of multi-scale temporal representations that force the motion context to be richly described at various levels of temporal resolution. Furthermore, a correction block is devised to eliminate the segmentation noise of silhouettes for getting more precise gait information. Subsequently, the temporal feature set and the spatial features are combined to comprehensively characterize gait processes. Extensive experiments are conducted on CASIA-B and OU-MVLP datasets, and the results achieve an outstanding identification performance, which has demonstrated the effectiveness of the proposed approach.