 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Multi-scale Bilateral Motion Network for Gait Recognition
Sep 26, 2022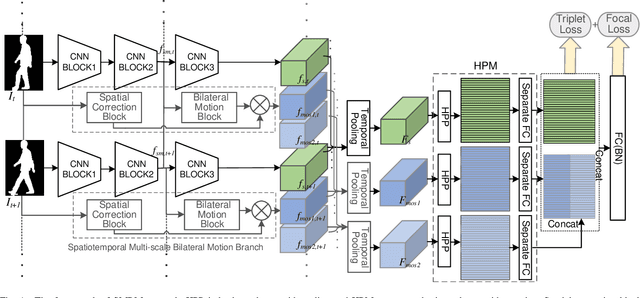


The critical goal of gait recognition is to acquire the inter-frame walking habit representation from the gait sequences. The relations between frames, however, have not received adequate attention in comparison to the intra-frame features. In this paper, motivated by optical flow, the bilateral motion-oriented features are proposed, which can allow the classic convolutional structure to have the capability to directly portray gait movement patterns at the feature level. Based on such features, we develop a set of multi-scale temporal representations that force the motion context to be richly described at various levels of temporal resolution. Furthermore, a correction block is devised to eliminate the segmentation noise of silhouettes for getting more precise gait information. Subsequently, the temporal feature set and the spatial features are combined to comprehensively characterize gait processes. Extensive experiments are conducted on CASIA-B and OU-MVLP datasets, and the results achieve an outstanding identification performance, which has demonstrated the effectiveness of the proposed approach.
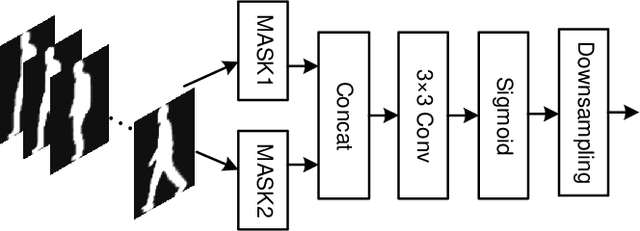
Sequential convolutional network for behavioral pattern extraction in gait recognition
Apr 23, 2021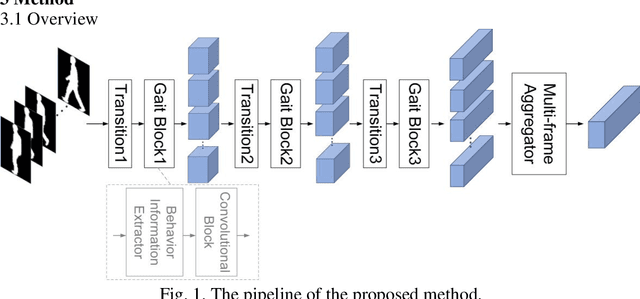
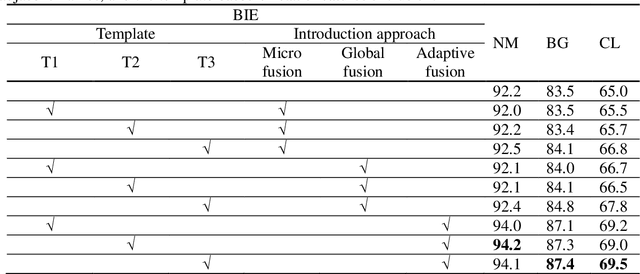
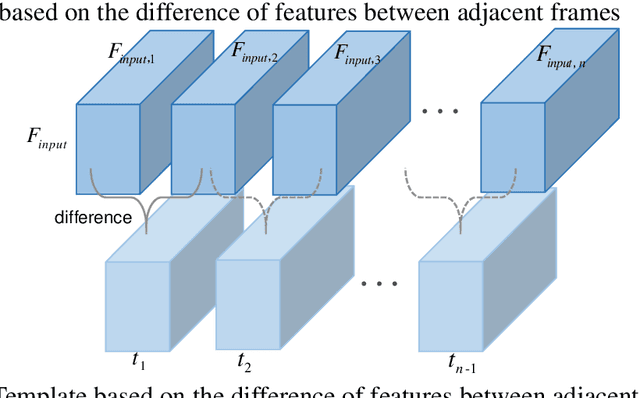
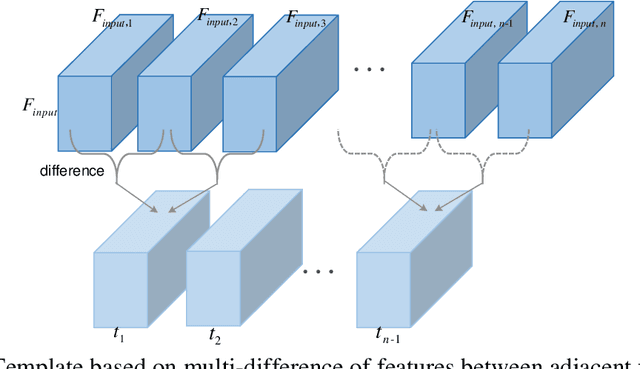
As a unique and promising biometric, video-based gait recognition has broad applications. The key step of this methodology is to learn the walking pattern of individuals, which, however, often suffers challenges to extract the behavioral feature from a sequence directly. Most existing methods just focus on either the appearance or the motion pattern. To overcome these limitations, we propose a sequential convolutional network (SCN) from a novel perspective, where spatiotemporal features can be learned by a basic convolutional backbone. In SCN, behavioral information extractors (BIE) are constructed to comprehend intermediate feature maps in time series through motion templates where the relationship between frames can be analyzed, thereby distilling the information of the walking pattern. Furthermore, a multi-frame aggregator in SCN performs feature integration on a sequence whose length is uncertain, via a mobile 3D convolutional layer. To demonstrate the effectiveness, experiments have been conducted on two popular public benchmarks, CASIA-B and OU-MVLP, and our approach is demonstrated superior performance, comparing with the state-of-art methods.